Appearance

Pandas
Pengenalan Pandas
Pustaka Pandas
Pandas adalah library open-source di Python yang digunakan untuk manipulasi dan analisis data. Library ini menyediakan dua struktur data utama: Series dan DataFrame, yang memudahkan pengolahan data dalam berbagai format seperti CSV, Excel, JSON, dan database SQL.
Instalasi dan Setup Pandas
Jika Pandas belum terinstall, Anda bisa menginstalnya dengan pip:
bash
pip install pandasSetelah instalasi selesai, impor Pandas di Python:
python
import pandas as pdStruktur Data Utama: Series & DataFrame
Series
Series adalah struktur data Pandas yang mirip dengan array satu dimensi (mirip dengan list di Python), tetapi memiliki index secara default.
Contoh penggunaan Series
python
import pandas as pd
# Membuat Series dari list
data = [10, 20, 30, 40]
series = pd.Series(data)
print(series)Output:
0 10
1 20
2 30
3 40
dtype: int64Kita juga bisa menentukan index secara manual:
python
series_custom_index = pd.Series(data, index=['a', 'b', 'c', 'd'])
print(series_custom_index)Output:
a 10
b 20
c 30
d 40
dtype: int64DataFrame
DataFrame adalah struktur data dua dimensi seperti tabel, terdiri dari baris dan kolom, mirip dengan spreadsheet atau tabel di database.
Contoh membuat DataFrame dari dictionary
python
data = {
'Nama': ['Alice', 'Bob', 'Charlie'],
'Umur': [25, 30, 35],
'Kota': ['Jakarta', 'Bandung', 'Surabaya']
}
df = pd.DataFrame(data)
print(df)Output:
Nama Umur Kota
0 Alice 25 Jakarta
1 Bob 30 Bandung
2 Charlie 35 SurabayaMembaca dan Menulis Data
Pandas mendukung berbagai format data, seperti CSV, Excel, JSON, dan SQL database.
1. CSV (pd.read_csv, .to_csv)
Membaca file CSV
python
df = pd.read_csv('data.csv') # Membaca file CSV
print(df.head()) # Menampilkan 5 baris pertamaMenyimpan DataFrame ke CSV
python
df.to_csv('hasil.csv', index=False) # Menyimpan tanpa menyertakan index2. Excel (pd.read_excel, .to_excel)
Membaca file Excel
python
df = pd.read_excel('data.xlsx', sheet_name='Sheet1') # Membaca sheet tertentu
print(df.head())Menyimpan DataFrame ke Excel
python
df.to_excel('hasil.xlsx', index=False, sheet_name='Output')3. JSON (pd.read_json, .to_json)
Membaca file JSON
python
df = pd.read_json('data.json')
print(df.head())Menyimpan DataFrame ke JSON
python
df.to_json('hasil.json', orient='records')4. Database SQLite (pd.read_sql, .to_sql)
Untuk membaca atau menulis ke database SQL, kita memerlukan SQLAlchemy. Instal terlebih dahulu dengan:
bash
pip install sqlalchemyMembaca data dari database SQLite
python
from sqlalchemy import create_engine
# Buat koneksi ke database SQLite
engine = create_engine('sqlite:///database.db')
# Membaca data dari tabel "users"
df = pd.read_sql('SELECT * FROM users', con=engine)
print(df.head())Menyimpan DataFrame ke database SQLite
python
df.to_sql('users_copy', con=engine, index=False, if_exists='replace')if_exists='replace' berarti jika tabel sudah ada, akan ditimpa.
Database PostgreSQL
Untuk membaca atau menulis ke database PostgreSQL database, berikut langkah-langkahnya:
1. Instalasi Paket yang Diperlukan
Pastikan pandas dan psycopg2 sudah terinstal:
sh
pip install pandas psycopg22. Membuat Koneksi ke PostgreSQL
Koneksi langsung menggunakan psycopg2:
python
import psycopg2
import pandas as pd
# Konfigurasi koneksi PostgreSQL
conn = psycopg2.connect(
dbname="your_database",
user="your_username",
password="your_password",
host="localhost", # atau IP server PostgreSQL
port="5432"
)3. Membaca Data dari PostgreSQL
Menggunakan pd.read_sql() dengan koneksi psycopg2:
python
import pandas as pd
df = pd.read_sql_query("SELECT * FROM users", conn)
print(df.head()) # Menampilkan 5 baris pertama4. Menyimpan DataFrame ke PostgreSQL
Karena psycopg2 tidak memiliki metode to_sql(), kita harus menggunakan copy_from() untuk menyimpan DataFrame:
Cara 1: Menggunakan copy_from() untuk Menyimpan CSV ke PostgreSQL
python
import io
# Konversi DataFrame ke format CSV dalam memori
output = io.StringIO()
df.to_csv(output, sep='\t', index=False, header=False)
output.seek(0)
# Simpan ke database PostgreSQL menggunakan copy_from()
with conn.cursor() as cur:
cur.copy_from(output, 'users_copy', null='') # Tabel "users_copy" akan dibuat
conn.commit()Cara 2: Menyisipkan Data dengan executemany()
Jika tabel users_copy sudah ada dan kita ingin menambahkan data:
python
with conn.cursor() as cur:
for _, row in df.iterrows():
cur.execute(
"INSERT INTO users_copy (id, name, email) VALUES (%s, %s, %s)",
(row['id'], row['name'], row['email'])
)
conn.commit()5. Menutup Koneksi
Jangan lupa menutup koneksi setelah selesai:
python
conn.close()Catatan
| Metode | Kelebihan | Kekurangan |
|---|---|---|
read_sql() | Mudah digunakan | Membutuhkan sqlalchemy untuk koneksi |
copy_from() | Sangat cepat untuk banyak data | Format harus CSV atau TSV |
executemany() | Fleksibel untuk penyisipan data | Kurang optimal untuk jumlah besar |
Untuk membaca data, pd.read_sql() lebih praktis.
Untuk menyimpan data, copy_from() lebih cepat daripada executemany(), terutama untuk dataset besar.
Manipulasi DataFrame & Series dengan Pandas
Pada bagian ini, kita akan membahas teknik manipulasi data menggunakan Pandas, termasuk cara memilih data, menangani missing values, mengubah tipe data, menyortir data, serta mengganti nama kolom dan index.
Indexing & Selection
1. .loc[] vs .iloc[]
Metode .loc[] dan .iloc[] digunakan untuk memilih subset data dari DataFrame, tetapi memiliki perbedaan dalam cara penggunaannya:
.loc[]: Mengakses data berdasarkan label (nama index atau nama kolom)..iloc[]: Mengakses data berdasarkan posisi (index numerik).
Contoh DataFrame
python
import pandas as pd
data = {
'Nama': ['Alice', 'Bob', 'Charlie'],
'Umur': [25, 30, 35],
'Kota': ['Jakarta', 'Bandung', 'Surabaya']
}
df = pd.DataFrame(data, index=['A', 'B', 'C'])
print(df)Output:
Nama Umur Kota
A Alice 25 Jakarta
B Bob 30 Bandung
C Charlie 35 SurabayaMenggunakan .loc[] (berdasarkan label)
python
print(df.loc['A']) # Mengambil baris dengan label 'A'
print(df.loc['B', 'Nama']) # Mengambil nilai dari baris 'B' dan kolom 'Nama'
print(df.loc[:, ['Nama', 'Umur']]) # Mengambil semua baris dan hanya kolom 'Nama' & 'Umur'Menggunakan .iloc[] (berdasarkan posisi index)
python
print(df.iloc[0]) # Mengambil baris pertama
print(df.iloc[1, 0]) # Mengambil nilai dari baris ke-1, kolom ke-0
print(df.iloc[:, [0, 1]]) # Mengambil semua baris dan hanya kolom ke-0 dan ke-12. Boolean Indexing
Boolean indexing digunakan untuk menyaring data berdasarkan kondisi tertentu.
Contoh: Memilih baris berdasarkan kondisi
python
print(df[df['Umur'] > 28]) # Memilih baris di mana 'Umur' lebih dari 28Output:
Nama Umur Kota
B Bob 30 Bandung
C Charlie 35 SurabayaMenggunakan beberapa kondisi (& untuk AND, | untuk OR)
python
print(df[(df['Umur'] > 25) & (df['Kota'] == 'Bandung')])3. Menambahkan & Menghapus Kolom
Menambahkan kolom baru dengan df.assign()
python
df = df.assign(Gaji=[5000, 7000, 6000])
print(df)Menghapus kolom dengan df.drop()
python
df = df.drop(columns=['Gaji']) # Menghapus kolom 'Gaji'
print(df)Menangani Missing Values
1. Mengecek missing values dengan .isnull()
python
df = pd.DataFrame({
'Nama': ['Alice', 'Bob', None],
'Umur': [25, None, 35],
'Kota': ['Jakarta', 'Bandung', 'Surabaya']
})
print(df.isnull()) # Menampilkan True jika ada nilai yang hilang2. Menghapus missing values dengan .dropna()
python
df_cleaned = df.dropna() # Menghapus baris yang memiliki missing values
print(df_cleaned)3. Mengisi missing values dengan .fillna()
python
df_filled = df.fillna({'Nama': 'Unknown', 'Umur': df['Umur'].mean()})
print(df_filled)Mengubah Tipe Data (df.astype())
Sering kali, tipe data dalam DataFrame perlu diubah agar sesuai dengan kebutuhan analisis.
Contoh mengubah tipe data kolom
python
df = pd.DataFrame({'Angka': ['1', '2', '3']})
df['Angka'] = df['Angka'].astype(int) # Mengubah tipe data dari string ke integer
print(df.dtypes) # Menampilkan tipe data setiap kolomSorting & Ordering Data
1. Sorting berdasarkan nilai kolom (df.sort_values())
python
df = pd.DataFrame({
'Nama': ['Alice', 'Bob', 'Charlie'],
'Umur': [35, 30, 25]
})
df_sorted = df.sort_values(by='Umur', ascending=True)
print(df_sorted)2. Sorting berdasarkan index (df.sort_index())
python
df_sorted_index = df.sort_index()
print(df_sorted_index)Rename Kolom & Index (df.rename())
1. Mengubah nama kolom
python
df_renamed = df.rename(columns={'Nama': 'Name', 'Umur': 'Age'})
print(df_renamed)2. Mengubah nama index
python
df = df.rename(index={0: 'A', 1: 'B', 2: 'C'})
print(df).loc[]vs.iloc[]: .loc[] berdasarkan label, .iloc[] berdasarkan posisi.- Boolean Indexing: Memfilter data dengan kondisi tertentu.
- Menambah/Menghapus Kolom:
df.assign()untuk menambah.df.drop()untuk menghapus.
- Menangani Missing Values:
.isnull()untuk mendeteksi..dropna()untuk menghapus baris yang memiliki missing values..fillna()untuk mengganti nilai yang hilang.
- Mengubah Tipe Data:
df.astype()untuk konversi tipe data. - Sorting Data:
df.sort_values()untuk mengurutkan berdasarkan nilai kolom.df.sort_index()untuk mengurutkan berdasarkan index.
- Rename Kolom & Index:
df.rename()untuk mengganti nama kolom atau index.
Axes di Pandas
Dalam Pandas, axes mengacu pada sumbu data yang digunakan untuk mengindeks baris dan kolom:
- axis=0 → Baris (index)
- axis=1 → Kolom (columns)
Setiap DataFrame memiliki dua sumbu:
df.axes[0]→ Index (baris)df.axes[1]→ Nama kolom
Contoh Penggunaan Axes
1. Melihat Axes dari DataFrame
python
import pandas as pd
data = {
'Nama': ['Alice', 'Bob', 'Charlie'],
'Umur': [25, 30, 35],
'Kota': ['Jakarta', 'Bandung', 'Surabaya']
}
df = pd.DataFrame(data)
print(df.axes) # Menampilkan daftar index dan kolomOutput:
[RangeIndex(start=0, stop=3, step=1), Index(['Nama', 'Umur', 'Kota'], dtype='object')]df.axes[0]→ Baris (index):RangeIndex(start=0, stop=3, step=1)df.axes[1]→ Kolom:Index(['Nama', 'Umur', 'Kota'], dtype='object')
Penggunaan Axes dalam Operasi Pandas
Beberapa fungsi di Pandas menggunakan parameter axis untuk menentukan apakah operasi dilakukan pada baris (axis=0) atau kolom (axis=1).
2. Menghapus Data dengan axis
a. Menghapus Baris (axis=0)
python
df_dropped = df.drop(index=[1]) # Menghapus baris dengan index 1 (Bob)
print(df_dropped)b. Menghapus Kolom (axis=1)
python
df_dropped_col = df.drop(columns=['Kota']) # Menghapus kolom 'Kota'
print(df_dropped_col)3. Operasi pada Baris vs Kolom dengan axis
Menjumlahkan Semua Baris (axis=0)
python
print(df[['Umur']].sum(axis=0)) # Menjumlahkan setiap kolom (total Umur)Output:
Umur 90
dtype: int64Menjumlahkan Semua Kolom (axis=1)
python
df['Total_Char'] = df[['Nama', 'Kota']].apply(lambda x: x.str.len().sum(), axis=1)
print(df)Output:
Nama Umur Kota Total_Char
0 Alice 25 Jakarta 12
1 Bob 30 Bandung 10
2 Charlie 35 Surabaya 13Catatan penting
- Pandas memiliki axes (sumbu) yang mengacu pada baris (`axis=0`) dan kolom (`axis=1`).
- `df.axes[0]` → Menunjukkan indeks baris.
- `df.axes[1]` → Menunjukkan nama kolom.
- Operasi dengan `axis=0` → Berlaku pada baris (misalnya, `df.drop(index=...)`).
- Operasi dengan `axis=1` → Berlaku pada kolom (misalnya, `df.drop(columns=...)`).
Pemahaman tentang axes sangat penting untuk manipulasi data yang efisien di Pandas.
Transformasi & Manipulasi Data di Pandas
Pandas menyediakan berbagai metode untuk mengubah dan memanipulasi data dengan lebih mudah dan efisien. Berikut adalah penjelasan dan contoh kodenya:
Apply fungsi ke DataFrame
Pandas memiliki beberapa metode untuk menerapkan fungsi ke elemen-elemen dalam DataFrame atau Series:
df.apply()→ Menerapkan fungsi ke setiap baris atau kolomdf.map()→ Digunakan untukSeries(hanya satu kolom)df.applymap()→ Menerapkan fungsi ke setiap elemen dalamDataFrame
Contoh:
python
import pandas as pd
# Contoh DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# Menggunakan apply pada kolom
df['A_kuadrat'] = df['A'].apply(lambda x: x**2)
# Menggunakan map (hanya untuk Series)
df['B_kali2'] = df['B'].map(lambda x: x * 2)
# Menggunakan applymap untuk setiap elemen dalam DataFrame
df = df.applymap(lambda x: x + 10)
print(df)Menggunakan Lambda Function di Pandas
lambda function banyak digunakan untuk transformasi cepat.
Contoh:
python
df['A'] = df['A'].apply(lambda x: x * 2 if x % 2 == 0 else x + 1)
print(df)Aggregasi & Statistik Deskriptif
Pandas menyediakan berbagai metode untuk analisis statistik deskriptif:
.describe()→ Ringkasan statistik dasar.mean()→ Rata-rata.sum()→ Total nilai.std()→ Standar deviasi.value_counts()→ Menghitung frekuensi unik
Contoh:
python
df = pd.DataFrame({
'A': [10, 20, 30, 40, 50],
'B': [5, 15, 25, 35, 45]
})
print(df.describe()) # Statistik ringkasan
print(df['A'].mean()) # Rata-rata kolom A
print(df['B'].value_counts()) # Jumlah nilai unik dalam kolom BGrouping Data
Grouping digunakan untuk mengelompokkan data berdasarkan kategori tertentu.
Contoh:
python
df = pd.DataFrame({
'Kategori': ['A', 'A', 'B', 'B', 'C'],
'Nilai': [10, 20, 30, 40, 50]
})
# Mengelompokkan berdasarkan kategori dan menghitung rata-rata
grouped = df.groupby('Kategori').mean()
print(grouped)Pivot & Melting Data
df.pivot_table()→ Untuk merangkum data dalam bentuk tabel pivotpd.melt()→ Mengubah data lebar menjadi format panjang
Contoh:
python
df = pd.DataFrame({
'Nama': ['Alice', 'Bob', 'Charlie'],
'Matematika': [80, 90, 85],
'Fisika': [75, 95, 80]
})
# Melting data
melted = pd.melt(df, id_vars=['Nama'], var_name='Mata_Pelajaran', value_name='Nilai')
print(melted)Merging, Joining, & Concatenation
Pandas menyediakan beberapa metode untuk menggabungkan DataFrame:
pd.merge()→ Menggabungkan berdasarkan kolom tertentu (seperti SQL JOIN).concat()→ Menggabungkan secara vertikal atau horizontal.join()→ Berguna untuk menggabungkan berdasarkan indeks
Contoh Merge:
python
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Nama': ['A', 'B', 'C']})
df2 = pd.DataFrame({'ID': [1, 2, 3], 'Nilai': [90, 85, 88]})
# Merge berdasarkan kolom ID
merged_df = pd.merge(df1, df2, on='ID')
print(merged_df)Contoh Concat:
python
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
# Menggabungkan secara vertikal
concatenated = pd.concat([df1, df2], ignore_index=True)
print(concatenated)Analisis Data & Visualisasi dengan Pandas
Pandas menyediakan fitur visualisasi data yang sederhana, yang memudahkan pengguna dalam melakukan analisis eksploratif.
Untuk menampilkan gambarnya diperlukan pustaka Matplotlib.
Basic Plotting dengan Pandas Menggunakan Matplotlib (df.plot())
Pandas memiliki metode .plot() yang memanfaatkan Matplotlib di backend. Beberapa jenis plot yang umum digunakan:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Contoh DataFrame
data = {
"Tahun": [2018, 2019, 2020, 2021, 2022],
"Penjualan": [100, 150, 200, 250, 300]
}
df = pd.DataFrame(data)
# Line plot
df.plot(x="Tahun", y="Penjualan", kind="line", marker="o", title="Tren Penjualan")
# Tampilkan plot
plt.show()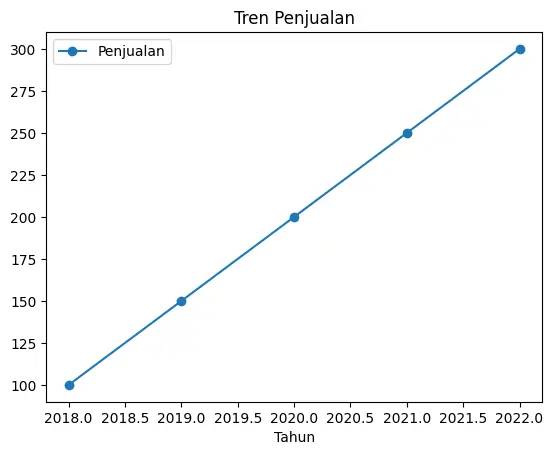
Penjelasan:
kind="line"→ Membuat grafik garis.marker="o"→ Memberi tanda pada setiap titik data.title="Tren Penjualan"→ Menambahkan judul.
Histogram, Boxplot, Scatter Plot
1. Histogram (kind="hist")
Histogram berguna untuk melihat distribusi data numerik.
python
df["Penjualan"].plot(kind="hist", bins=5, title="Distribusi Penjualan")
plt.show()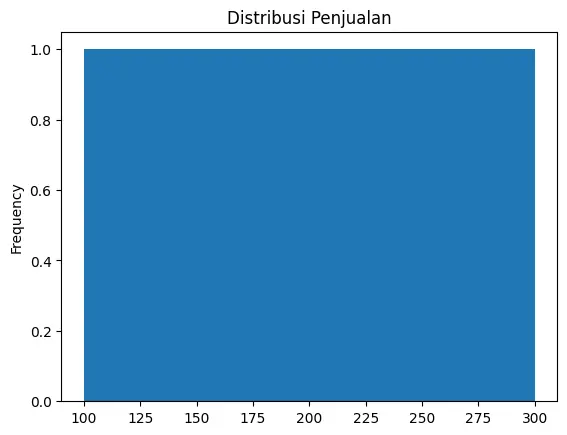
bins=5→ Menentukan jumlah kelompok data.
2. Boxplot (kind="box")
Digunakan untuk melihat distribusi data dan mendeteksi outlier.
python
df["Penjualan"].plot(kind="box", title="Boxplot Penjualan")
plt.show()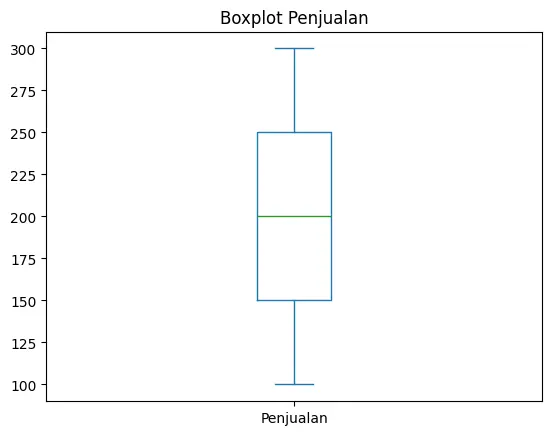
3. Scatter Plot (kind="scatter")
Digunakan untuk melihat hubungan antar variabel.
python
df.plot(x="Tahun", y="Penjualan", kind="scatter", title="Scatter Plot Penjualan")
plt.show()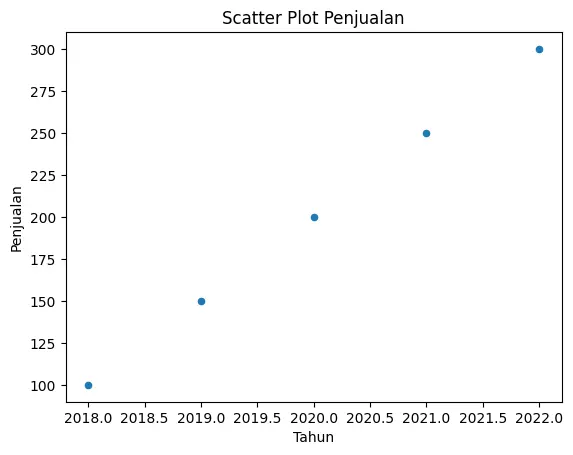
Correlation Analysis (df.corr())
Analisis korelasi digunakan untuk melihat hubungan antar variabel numerik.
python
# Contoh data tambahan
df["Biaya_Iklan"] = [10, 15, 20, 25, 30]
# Hitung korelasi
corr_matrix = df.corr()
print(corr_matrix)Output:
Tahun Penjualan Biaya_Iklan
Tahun 1.000 1.000 1.000
Penjualan 1.000 1.000 1.000
Biaya_Iklan 1.000 1.000 1.000- Nilai mendekati 1 → Korelasi positif yang kuat.
- Nilai mendekati -1 → Korelasi negatif yang kuat.
- Nilai mendekati 0 → Tidak ada hubungan yang signifikan.
Eksplorasi Data dan Analisis Data (EDA)
Exploratory Data Analysis (EDA) adalah proses memahami, membersihkan, dan menganalisis dataset sebelum digunakan dalam model atau pengambilan keputusan. Proses ini sering melibatkan pandas untuk menyiapkan data yang siap dianalisis lebih lanjut.
Memahami Dataset
Langkah pertama dalam EDA adalah memahami dataset yang digunakan. Dataset bisa berasal dari Kaggle, Open Data, atau sumber internal lainnya.
Contoh: Memuat dataset dan melihat struktur datanya
python
import pandas as pd
# Membaca dataset dari file CSV
df = pd.read_csv("data.csv")
# Menampilkan 5 baris pertama dari dataset
print(df.head())
# Menampilkan 5 baris terakhir dari dataset
print(df.tail())
# Melihat informasi dataset (jumlah kolom, tipe data, jumlah data yang hilang, dll.)
print(df.info())Pembersihan dan Persiapan Data
1. Menangani Nilai yang Hilang (Missing Values)
Data yang hilang dapat menyebabkan hasil analisis menjadi tidak akurat, sehingga perlu ditangani dengan beberapa metode berikut:
python
# Mengecek jumlah missing values di setiap kolom
print(df.isnull().sum())
# Menghapus baris yang memiliki missing values
df_cleaned = df.dropna()
# Mengisi nilai yang hilang dengan rata-rata (mean) kolom tersebut
df_filled = df.fillna(df.mean())2. Mendeteksi dan Menghapus Duplikasi Data
Data duplikat dapat menyebabkan bias dalam analisis.
python
# Mengecek jumlah data duplikat
print(df.duplicated().sum())
# Menghapus data yang duplikat
df = df.drop_duplicates()3. Menangani Outlier (Data Pencilan)
Outlier dapat mempengaruhi hasil analisis dan perlu ditangani dengan metode statistik, seperti Interquartile Range (IQR).
python
import numpy as np
# Menentukan batas outlier dengan metode IQR (Interquartile Range)
Q1 = df["nilai"].quantile(0.25)
Q3 = df["nilai"].quantile(0.75)
IQR = Q3 - Q1
# Menentukan batas bawah dan atas untuk outlier
batas_bawah = Q1 - 1.5 * IQR
batas_atas = Q3 + 1.5 * IQR
# Menghapus outlier dari dataset
df = df[(df["nilai"] >= batas_bawah) & (df["nilai"] <= batas_atas)]Feature Engineering dan Transformasi Data
Feature Engineering adalah proses membuat fitur baru berdasarkan data yang sudah ada agar lebih informatif.
1. Membuat Kolom Baru
python
# Menambahkan kolom baru berdasarkan perhitungan dari kolom lain
df["total_pendapatan"] = df["harga"] * df["jumlah_terjual"]2. Encoding Variabel Kategorikal
Jika terdapat kolom dengan nilai kategorikal (teks), kita perlu mengonversinya menjadi numerik.
python
# Mengubah kategori teks menjadi angka dengan one-hot encoding
df = pd.get_dummies(df, columns=["kategori"], drop_first=True)Visualisasi Data untuk Eksplorasi
Visualisasi data membantu memahami distribusi data, pola, dan hubungan antar variabel.
1. Histogram (Distribusi Data)
python
import matplotlib.pyplot as plt
# Membuat histogram untuk melihat distribusi nilai
df["nilai"].hist(bins=20)
plt.xlabel("Nilai")
plt.ylabel("Frekuensi")
plt.title("Distribusi Nilai")
plt.show()2. Scatter Plot (Hubungan Antar Variabel)
python
# Scatter plot untuk melihat hubungan antara dua variabel
plt.scatter(df["harga"], df["jumlah_terjual"])
plt.xlabel("Harga")
plt.ylabel("Jumlah Terjual")
plt.title("Hubungan antara Harga dan Jumlah Terjual")
plt.show()3. Analisis Korelasi
python
# Melihat korelasi antar variabel dalam dataset
print(df.corr())
# Visualisasi heatmap korelasi
import seaborn as sns
plt.figure(figsize=(8, 6))
sns.heatmap(df.corr(), annot=True, cmap="coolwarm", fmt=".2f")
plt.title("Heatmap Korelasi")
plt.show()Catatan
- EDA membantu memahami dataset sebelum analisis lebih lanjut.
- Langkah penting dalam EDA termasuk pembersihan data, transformasi fitur, dan visualisasi data.
- Visualisasi data dengan histogram, scatter plot, dan heatmap membantu dalam pengambilan keputusan.
Analisis Time Series & Manipulasi Data Lanjutan
Time Series Analysis adalah teknik untuk menganalisis data yang dikumpulkan dalam interval waktu tertentu, seperti harga saham harian, suhu harian, atau jumlah pengunjung situs web setiap jam. Pandas menyediakan berbagai fungsi untuk menangani dan menganalisis data time series.
Parsing Waktu di Pandas (pd.to_datetime())
Data time series sering kali disimpan dalam format string, sehingga perlu dikonversi ke format datetime menggunakan pd.to_datetime().
Contoh: Konversi kolom tanggal menjadi format datetime
python
import pandas as pd
# Contoh data dengan kolom tanggal dalam bentuk string
data = {"tanggal": ["2024-02-01", "2024-02-02", "2024-02-03"], "nilai": [100, 120, 130]}
df = pd.DataFrame(data)
# Konversi kolom "tanggal" menjadi datetime
df["tanggal"] = pd.to_datetime(df["tanggal"])
# Cek tipe data setelah konversi
print(df.dtypes)Keuntungan menggunakan datetime format:
- Memudahkan operasi berbasis waktu (filtering, grouping, dll.).
- Bisa digunakan untuk analisis lebih lanjut seperti resampling dan rolling statistics.
Resampling & Rolling Statistics
Resampling digunakan untuk mengubah frekuensi data time series (misalnya dari harian ke bulanan), sedangkan rolling statistics digunakan untuk menghitung statistik berbasis jendela waktu tertentu.
1. Resampling Time Series (df.resample())
Resampling berguna untuk mengubah tingkat granularitas data, seperti mengonversi data harian ke mingguan atau bulanan.
python
# Contoh data time series harian
df.set_index("tanggal", inplace=True)
# Resampling data ke frekuensi mingguan, menggunakan rata-rata nilai
df_mingguan = df.resample("W").mean()
print(df_mingguan)Kode Resampling berdasarkan frekuensi digunakan 'W'
"W"→ Mingguan
Kode resampling tersebut adalah ketentuan standar di Pandas untuk frekuensi waktu dalam metode .resample(). Berikut adalah beberapa kode frekuensi yang umum digunakan:
Kode Resampling berdasarkan Frekuensi Waktu di Pandas
| Kode | Deskripsi | Contoh |
|---|---|---|
"D" | Harian | df.resample("D").mean() |
"W" | Mingguan (Akhir Minggu: Minggu) | df.resample("W").sum() |
"M" | Bulanan (Akhir Bulan) | df.resample("M").mean() |
"Q" | Kuartalan (Akhir Kuartal) | df.resample("Q").sum() |
"Y" | Tahunan (Akhir Tahun: 31 Desember) | df.resample("Y").mean() |
"H" | Per Jam | df.resample("H").sum() |
"T" atau "min" | Per Menit | df.resample("T").mean() |
"S" | Per Detik | df.resample("S").sum() |
"B" | Hari Kerja (Senin–Jumat) | df.resample("B").mean() |
"W-MON" | Mingguan dengan akhir Senin | df.resample("W-MON").sum() |
"MS" | Awal Bulan | df.resample("MS").mean() |
"QS" | Awal Kuartal | df.resample("QS").sum() |
"YS" | Awal Tahun | df.resample("YS").mean() |
Contoh Penggunaan
- Resampling ke format bulanan dengan rata-rata nilaipython
df.resample("M").mean() - Resampling ke format mingguan dengan total nilaipython
df.resample("W").sum() - Resampling ke format kuartalan dengan nilai maksimumpython
df.resample("Q").max()
Pandas juga mendukung kombinasi angka dan kode waktu, misalnya:
"3D"→ Setiap 3 hari"2W"→ Setiap 2 minggu"6H"→ Setiap 6 jam
2. Rolling Statistics (df.rolling())
Rolling statistics digunakan untuk menghitung nilai statistik bergerak (moving average, rolling sum, dll.), yang berguna untuk analisis tren dan pola dalam data time series.
python
# Menghitung rata-rata bergerak (moving average) selama 3 hari terakhir
df["rolling_mean"] = df["nilai"].rolling(window=3).mean()
print(df)Kegunaan rolling statistics:
- Menghaluskan fluktuasi data untuk melihat tren yang lebih jelas.
- Mengurangi dampak outlier dalam data time series.
Time Zone Handling (df.tz_localize(), df.tz_convert())
Data time series sering kali memiliki informasi zona waktu yang perlu dikelola dengan benar.
1. Menambahkan Zona Waktu (df.tz_localize())
Jika dataset tidak memiliki informasi zona waktu, kita bisa menetapkannya dengan tz_localize().
python
# Menambahkan zona waktu ke kolom datetime
df.index = df.index.tz_localize("UTC")
print(df.index)2. Konversi Zona Waktu (df.tz_convert())
Jika kita ingin mengubah zona waktu dataset ke zona waktu lain, gunakan tz_convert().
python
# Mengonversi zona waktu dari UTC ke Asia/Jakarta
df.index = df.index.tz_convert("Asia/Jakarta")
print(df.index)Contoh Zona Waktu Umum:
"UTC"→ Waktu Universal"Asia/Jakarta"→ Waktu Indonesia Barat (WIB)"Asia/Makassar"→ Waktu Indonesia Tengah (WITA)"Asia/Jayapura"→ Waktu Indonesia Timur (WIT)
Mengapa penting menangani zona waktu?
- Data time series dari berbagai sumber bisa memiliki zona waktu yang berbeda.
- Mencegah kesalahan dalam analisis yang melibatkan perbedaan waktu antar lokasi.
- Parsing datetime (
pd.to_datetime()) penting untuk mengubah data string menjadi format datetime yang bisa dianalisis lebih lanjut. - Resampling (
df.resample()) digunakan untuk mengubah granularitas data time series (harian ke mingguan, dll.). - Rolling statistics (
df.rolling()) digunakan untuk menghitung moving average dan tren data. - Time zone handling (
df.tz_localize()&df.tz_convert()) penting untuk memastikan konsistensi zona waktu dalam analisis data.
Optimisasi & Performa dalam Pandas
Ketika bekerja dengan data dalam jumlah besar, performa menjadi faktor penting agar analisis tetap efisien dan tidak membebani sistem. Berikut adalah beberapa teknik optimisasi yang dapat digunakan di Pandas untuk meningkatkan performa pemrosesan data:
1. Handling Large Datasets dengan dtype yang Optimal
Pandas secara default mengalokasikan tipe data (dtype) berdasarkan isi kolom, tetapi sering kali ini tidak efisien. Dengan menentukan tipe data yang lebih ringan, kita bisa menghemat memori secara signifikan.
Contoh:
python
import pandas as pd
import numpy as np
# Tanpa optimisasi
df = pd.DataFrame({
'id': np.arange(1_000_000), # Default dtype: int64
'nilai': np.random.rand(1_000_000) # Default dtype: float64
})
print(df.memory_usage(deep=True)) # Lihat penggunaan memori
# Dengan optimisasi
df_opt = pd.DataFrame({
'id': np.arange(1_000_000, dtype=np.int32), # Menggunakan int32 daripada int64
'nilai': np.random.rand(1_000_000).astype(np.float32) # Menggunakan float32 daripada float64
})
print(df_opt.memory_usage(deep=True)) # Penggunaan memori lebih kecilMenggunakan tipe data yang lebih kecil (int32, float32, category untuk data kategorikal) dapat menghemat memori secara drastis, terutama untuk dataset besar.
2. Memproses Data dengan Chunk (pd.read_csv(chunksize=...))
Membaca seluruh dataset besar langsung ke dalam memori dapat menyebabkan MemoryError. Untuk menghindari ini, kita bisa menggunakan metode chunking, yaitu membaca data dalam bagian-bagian kecil (chunks).
Contoh:
python
chunk_size = 100_000 # Jumlah baris per chunk
chunks = pd.read_csv("data_besar.csv", chunksize=chunk_size)
total_rows = 0
for chunk in chunks:
total_rows += len(chunk)
print(f"Memproses {len(chunk)} baris...")
print(f"Total baris: {total_rows}")Dengan memproses data dalam bentuk chunk, kita bisa menangani dataset yang lebih besar dari kapasitas RAM tanpa kehabisan memori.
3. Menggunakan Pandas dengan Dask untuk Big Data
Jika dataset terlalu besar hingga tidak cukup di RAM, Dask bisa menjadi solusi. Dask adalah pustaka yang memungkinkan kita bekerja dengan Pandas secara paralel di beberapa core CPU atau bahkan dalam cluster komputasi.
Mengapa Dask?
✅ Dapat menangani dataset yang lebih besar dari RAM
✅ Mendukung pemrosesan paralel (lebih cepat)
✅ API mirip dengan Pandas, sehingga mudah digunakan
Contoh Penggunaan Dask:
python
import dask.dataframe as dd
# Membaca file CSV besar dengan Dask
df = dd.read_csv("data_besar.csv")
# Melakukan operasi mirip Pandas
df.groupby("kategori")["nilai"].mean().compute()Dask cocok untuk dataset yang sangat besar karena dapat memprosesnya secara bertahap dan menggunakan paralelisasi untuk mempercepat perhitungan.