Appearance
Linear Algebra
Pengantar
Aljabar linear adalah pondasi yang paling dasar dalam statistik maupun machine learning.
Aljabar linear adalah cabang matematika yang mempelajari vektor, matriks, ruang vektor, transformasi linear, dan sistem persamaan linear. Aljabar linear menyediakan alat dan konsep yang penting untuk memodelkan dan menyelesaikan masalah dalam berbagai bidang, termasuk fisika, ilmu komputer, statistik, dan machine learning.
Beberapa konsep dasar dalam aljabar linear meliputi:
- Vektor. Objek matematika yang memiliki magnitude (besar) dan arah.
- Matriks. Susunan bilangan dalam bentuk baris dan kolom.
- Operasi Matriks. Penjumlahan, perkalian, invers, dan transpose.
- Ruang Vektor: Kumpulan vektor yang memenuhi aturan tertentu.
- Transformasi Linear. Fungsi yang memetakan vektor dari satu ruang vektor ke ruang vektor lain.
- Nilai Eigen dan Vektor Eigen. Konsep yang berkaitan dengan skalar dan vektor yang mempertahankan arahnya setelah transformasi linear.
Fungsi Aljabar Linear dalam Machine Learning
Aljabar linear adalah fondasi utama dalam machine learning karena sebagian besar algoritma dan model machine learning bekerja dengan data yang direpresentasikan dalam bentuk vektor dan matriks. Berikut adalah beberapa fungsi aljabar linear dalam machine learning:
1. Representasi Data
- Data dalam machine learning sering direpresentasikan sebagai vektor (untuk satu sampel) atau matriks (untuk kumpulan sampel).
- Contoh: Jika Anda memiliki dataset dengan 1000 sampel dan 10 fitur, data tersebut dapat direpresentasikan sebagai matriks berukuran
.
2. Transformasi Data
- Aljabar linear digunakan untuk melakukan transformasi data, seperti scaling, rotasi, atau proyeksi.
- Contoh: Principal Component Analysis (PCA) menggunakan aljabar linear untuk mengurangi dimensi data dengan memproyeksikannya ke ruang berdimensi lebih rendah.
3. Optimisasi
- Banyak algoritma machine learning melibatkan optimisasi fungsi tujuan (objective function), yang sering kali melibatkan operasi matriks dan vektor.
- Contoh: Dalam regresi linear, kita mencari vektor bobot
yang meminimalkan kesalahan prediksi.
4. Model Matematis
- Model machine learning seperti regresi linear, support vector machines (SVM), dan neural networks menggunakan operasi aljabar linear untuk menghitung prediksi.
- Contoh: Dalam neural networks, setiap lapisan (layer) melakukan operasi linear
diikuti oleh fungsi aktivasi non-linear.
5. Nilai Eigen dan Dekomposisi Matriks
- Nilai eigen dan dekomposisi matriks (seperti Singular Value Decomposition (SVD)) digunakan untuk analisis data dan reduksi dimensi.
- Contoh: SVD digunakan dalam rekomendasi sistem untuk mengurai matriks rating menjadi komponen-komponen utamanya.
6. Perhitungan Jarak dan Similaritas
- Aljabar linear digunakan untuk menghitung jarak antara vektor, seperti jarak Euclidean atau cosine similarity, yang penting dalam algoritma clustering dan klasifikasi.
- Contoh: Dalam k-means clustering, jarak antara titik data dan centroid dihitung menggunakan operasi vektor.
7. Deep Learning
- Deep learning sangat bergantung pada aljabar linear karena neural networks terdiri dari serangkaian transformasi linear dan non-linear.
- Contoh: Perkalian matriks digunakan untuk menghitung output setiap lapisan dalam neural network.
Contoh Penerapan Aljabar Linear dalam Machine Learning
Regresi Linear
- Model regresi linear memprediksi output (
) sebagai kombinasi linear dari fitur input ( ) dan vektor bobot ( ): - Di sini,
adalah matriks data, adalah vektor bobot, dan adalah bias.
- Model regresi linear memprediksi output (
Neural Networks
- Setiap lapisan dalam neural network melakukan operasi linear (
), di mana adalah matriks bobot, adalah vektor input, dan adalah bias.
- Setiap lapisan dalam neural network melakukan operasi linear (
PCA (Principal Component Analysis)
- PCA menggunakan dekomposisi matriks untuk menemukan arah (vektor eigen) yang memaksimalkan varians data, sehingga mengurangi dimensi data.
Struktur Data dalam Aljabar Linear:
- Vektor Vektor adalah objek dalam ruang vektor yang memiliki magnitude (panjang) dan arah. Mereka dapat diwakili sebagai kumpulan bilangan yang memiliki aturan penjumlahan dan perkalian dengan skalar. Vektor bisa dalam ruang 2D (seperti bidang) atau ruang 3D (seperti ruang tiga dimensi), tetapi konsep vektor tidak terbatas pada dimensi itu saja.
- Ruang Vektor Ruang vektor adalah himpunan vektor yang memenuhi aksioma-aksioma aljabar linear. Ruang tersebut dapat memiliki dimensi yang berbeda-beda. Misalnya, ruang vektor 2D terdiri dari semua vektor yang dapat diwakili oleh dua bilangan, dan ruang vektor 3D terdiri dari semua vektor yang dapat diwakili oleh tiga bilangan.
- Transformasi Linear Transformasi linear adalah fungsi matematika antara dua ruang vektor yang memelihara sifat-sifat aljabar linear. Transformasi ini memetakan vektor dari satu ruang ke ruang vektor lainnya, mempertahankan operasi penjumlahan vektor dan perkalian dengan skalar.
- Matriks Matriks adalah representasi aljabar linear yang terdiri dari baris dan kolom bilangan. Matriks dapat digunakan untuk merepresentasikan transformasi linear dan sistem persamaan linear. Operasi pada matriks termasuk penjumlahan, perkalian, dan invers matriks.
- Tensor Tensor adalah objek matematika yang umumnya memperluas konsep vektor dan matriks ke dimensi yang lebih tinggi. Mereka digunakan untuk merepresentasikan dan memanipulasi data yang memiliki struktur multidimensi. Tensor dapat memiliki berbagai orde, seperti tensor skalar (orde 0), vektor (orde 1), matriks (orde 2), dan tensor berorde tinggi lainnya.
Struktur Data dalam Aljabar Linear
Vector
Vektor adalah salah satu struktur data dasar dalam aljabar linear. Secara matematis, vektor adalah objek yang memiliki magnitude (panjang) dan arah. Vektor dapat direpresentasikan sebagai array atau daftar bilangan yang terurut, di mana setiap bilangan mewakili komponen vektor dalam suatu dimensi.
Contoh Vektor:
- Vektor 2D:
- Vektor 3D:
- Vektor
-dimensi:
Vektor dapat digunakan untuk merepresentasikan data seperti fitur dalam dataset, koordinat dalam ruang, atau bobot dalam model machine learning.
Operasi Dasar pada Vektor
Beberapa operasi dasar yang dapat dilakukan pada vektor meliputi:
- Penjumlahan Vektor: Menambahkan dua vektor dengan menambahkan komponen-komponennya.
- Perkalian dengan Skalar: Mengalikan setiap komponen vektor dengan suatu skalar.
- Dot Product (Perkalian Titik): Menghitung hasil kali titik antara dua vektor.
- Norm (Panjang Vektor): Menghitung magnitude (panjang) vektor.
Implementasi Vector dalam Numpy
Contoh berikut implementasi vector dalam numpy. NumPy adalah library Python untuk komputasi numerik. NumPy menyediakan objek ndarray (n-dimensional array) yang dapat digunakan untuk merepresentasikan vektor, matriks, dan tensor.
import numpy as np
# Membuat vektor
v = np.array([1, 2, 3]) # Vektor 1D
print("Vektor v:", v)
# Operasi dasar
v1 = np.array([1, 2])
v2 = np.array([3, 4])
# Penjumlahan
hasil_penjumlahan = v1 + v2
print("Hasil Penjumlahan:", hasil_penjumlahan)
# Dot product
dot_product = np.dot(v1, v2)
print("Dot Product:", dot_product)
# Norm (panjang vektor)
norm_v1 = np.linalg.norm(v1)
print("Norm v1:", norm_v1)Implementasi Vector dalam Scipy
SciPy adalah library yang dibangun di atas NumPy dan menyediakan fungsi-fungsi tambahan untuk komputasi ilmiah, termasuk operasi aljabar linear.
from scipy.linalg import norm
# Membuat vektor
v = np.array([1, 2, 3]) # Menggunakan NumPy untuk membuat vektor
# Menghitung norm
norm_v = norm(v)
print("Norm v:", norm_v)Implementasi Vektor dalam PyTorch
PyTorch adalah library machine learning yang menyediakan dukungan kuat untuk operasi aljabar linear, termasuk operasi pada vektor. Berikut adalah contoh implementasi vektor dan operasinya menggunakan PyTorch:
1. Membuat Vektor
python
import torch
# Membuat vektor 2D
v = torch.tensor([1.0, 2.0])
print("Vektor v:", v)
# Membuat vektor 3D
w = torch.tensor([1.0, 2.0, 3.0])
print("Vektor w:", w)2. Penjumlahan Vektor
python
# Penjumlahan dua vektor
v1 = torch.tensor([1.0, 2.0])
v2 = torch.tensor([3.0, 4.0])
hasil_penjumlahan = v1 + v2
print("Hasil Penjumlahan:", hasil_penjumlahan)3. Perkalian dengan Skalar
python
# Perkalian vektor dengan skalar
skalar = 2.0
hasil_perkalian = skalar * v1
print("Hasil Perkalian dengan Skalar:", hasil_perkalian)4. Dot Product (Perkalian Titik)
python
# Dot product antara dua vektor
dot_product = torch.dot(v1, v2)
print("Dot Product:", dot_product)5. Norm (Panjang Vektor)
python
# Menghitung norm (panjang) vektor
norm_v1 = torch.norm(v1)
print("Norm v1:", norm_v1)Penggabungan semua operasi di atas:
python
import torch
# Membuat vektor
v1 = torch.tensor([1.0, 2.0])
v2 = torch.tensor([3.0, 4.0])
# Penjumlahan vektor
hasil_penjumlahan = v1 + v2
print("Hasil Penjumlahan:", hasil_penjumlahan)
# Perkalian dengan skalar
skalar = 2.0
hasil_perkalian = skalar * v1
print("Hasil Perkalian dengan Skalar:", hasil_perkalian)
# Dot product
dot_product = torch.dot(v1, v2)
print("Dot Product:", dot_product)
# Norm (panjang vektor)
norm_v1 = torch.norm(v1)
print("Norm v1:", norm_v1)Output Program
Hasil Penjumlahan: tensor([4., 6.])
Hasil Perkalian dengan Skalar: tensor([2., 4.])
Dot Product: 11.0
Norm v1: 2.2361Penjelasan Output
Hasil Penjumlahan
Hasil Perkalian dengan Skalar
Dot Product
Norm v1
Tensor
Tensor adalah objek matematika yang digunakan untuk merepresentasikan hubungan multilinear antara himpunan vektor, skalar, dan objek-objek multilinear lainnya dalam ruang vektor. Tensor memiliki berbagai orde, misalnya, tensor orde pertama adalah vektor, tensor orde kedua adalah matriks, dan tensor orde tinggi memiliki struktur yang lebih kompleks.
PyTorch adalah library python yang digunakan untuk machine learning dan deep learning, dimana PyTorch menggunakan tensor sebagai dasar struktur data.
Apa itu tensor? Tensor adalah struktur data yang mirip dengan array multidimensi (seperti array NumPy), namun tensor di PyTorch memiliki beberapa keunggulan tambahan, terutama dalam konteks komputasi numerik untuk machine learning dan deep learning. Tensor di PyTorch memungkinkan operasi yang efisien, baik di CPU maupun GPU (dengan dukungan CUDA), yang sangat penting untuk komputasi besar yang dibutuhkan dalam training model deep learning.
Berikut adalah contoh-contoh tensor:
Tensor Orde Pertama (Vektor)
Vektor adalah tensor orde pertama yang memiliki satu set komponen. Contohnya:
Tensor Orde Kedua (Matriks)
Matriks adalah tensor orde kedua yang memiliki dua set indeks. Contohnya:
Tensor Orde Tinggi
Tensor orde tinggi memiliki struktur yang lebih kompleks dengan lebih dari dua set indeks. Misalnya, tensor orde tiga dapat direpresentasikan sebagai kubus bilangan:
Ini adalah representasi matematika dari tensor 3D yang memiliki 2 blok, setiap blok berisi matriks berukuran 3×4.
Penjelasan Tensor Orde Tiga (3D)
Tensor orde tiga adalah tensor yang memiliki tiga dimensi. Biasanya, tensor orde tiga bisa dilihat sebagai kumpulan matriks 2D, dan dalam kasus ini, kita memiliki dua matriks 3x4 yang membentuk tensor 3D.
Mari kita uraikan representasi matematika tensor 3D yang tersebut:
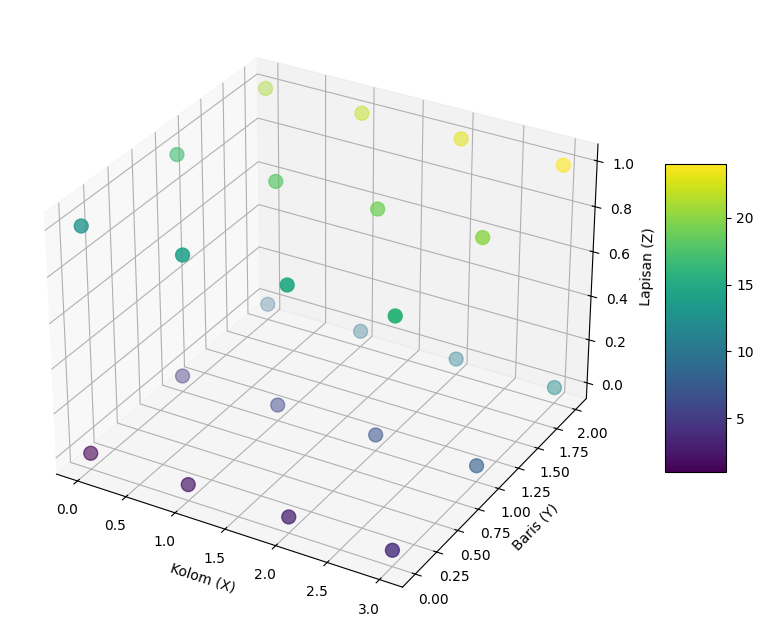
Penjelasan:
Tensor ini hanya memiliki dua lapisan, yaitu lapisan pertama di
Tensor 3D
- Memastikan hanya ada 2 lapisan sesuai dengan tensor yang diberikan, yaitu
yang terdiri dari 2 blok matriks .
- Memastikan hanya ada 2 lapisan sesuai dengan tensor yang diberikan, yaitu
Indeks
- Variabel
diatur dengan dua nilai, yaitu 0 dan 1, yang mewakili dua lapisan/slice, satu di dan satu lagi di .
- Variabel
Grid
xdanymengatur grid koordinat dalam 2D untuk kolom dan baris.zberfungsi sebagai kedalaman dan hanya berisi 2 lapisan.
Plot 3D:
- Plot akan menunjukkan dua lapisan di ruang 3D, dengan elemen-elemen yang diberi anotasi sesuai dengan nilai tensor.
- Plot akan menunjukkan 2 lapisan, yang hanya berisi 12 elemen per lapisan.
Aplikasi Tensor Orde Tiga
Tensor seperti ini sering digunakan dalam berbagai aplikasi, seperti:
- Citra berwarna (RGB): Setiap lapisan bisa merepresentasikan saluran warna yang berbeda (misalnya, merah, hijau, dan biru), dengan baris dan kolom mewakili dimensi spasial citra.
- Video: Di mana setiap lapisan mewakili frame yang berbeda dari video, dan setiap frame berisi piksel yang disusun dalam baris dan kolom.
Pemanfaatan Tensor 3D di PyTorch
Di PyTorch, tensor 3D sering digunakan dalam deep learning untuk merepresentasikan data dengan lebih dari dua dimensi (misalnya, citra atau video). Untuk membentuk tensor 3D seperti di atas, Anda dapat menggunakan kode berikut di PyTorch:
python
import torch
# Membuat tensor 3D dengan bentuk (2, 3, 4)
tensor_3d = torch.tensor([[[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]],
[[13, 14, 15, 16],
[17, 18, 19, 20],
[21, 22, 23, 24]]])
# Menampilkan tensor 3D
print(tensor_3d)Output:
tensor([[[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]],
[[13, 14, 15, 16],
[17, 18, 19, 20],
[21, 22, 23, 24]]])1. Scalars (Tensor Orde 0) dalam python
In [6]:
x = 25
xOut[6]:
25In [9]:
py_sum = x + y
py_sumOut[9]:
28In [10]:
type(py_sum)Out[10]:
intIn [11]:
x_float = 25.0
float_sum = x_float + y
float_sumOut[11]:
28.0In [12]:
type(float_sum)Out[12]:
floatScalars dalam PyTorch
In [13]:
import torchIn [14]:
x_pt = torch.tensor(25) # type specification optional, e.g.: dtype=torch.float16
x_ptOut[14]:
tensor(25)In [15]:
x_pt.shapeOut[15]:
torch.Size([])Vectors Sebagai Tensor Orde 1
Di PyTorch, vektor adalah tensor orde 1 yang hanya memiliki satu dimensi. Vektor ini dapat berisi berbagai jenis data seperti bilangan bulat, floating point, atau nilai lainnya. Kita juga dapat melakukan beberapa operasi pada vektor, termasuk transposisi dan membuat vektor nol.
1. Vektor (Tensor Orde 1)
Vektor adalah tensor yang memiliki satu dimensi. Secara matematis, vektor adalah himpunan nilai yang terorganisir dalam urutan tertentu, tetapi hanya memiliki satu dimensi.
Contoh membuat vektor di PyTorch:
python
import torch
# Membuat vektor (tensor orde 1)
vektor = torch.tensor([1, 2, 3, 4, 5])
print("Vektor:", vektor)Output:
Vektor: tensor([1, 2, 3, 4, 5])Di sini, vektor adalah tensor orde 1 dengan 5 elemen.
2. Transposisi Vektor
Transposisi pada vektor orde 1 pada dasarnya tidak mengubah vektor itu sendiri karena tidak ada dimensi kedua atau lebih. Namun, kita dapat melakukan perubahan bentuk atau struktur vektor, misalnya mengubahnya menjadi vektor kolom (tensor 2D) dengan dimensi (n, 1) atau sebaliknya.
Misalnya, kita bisa menganggap bahwa transposisi pada vektor satu dimensi ini adalah mengubah bentuknya menjadi bentuk vektor kolom atau vektor baris.
Mengubah vektor menjadi vektor kolom (dimensi (n, 1)):
python
# Mengubah vektor menjadi vektor kolom (tensor orde 2)
vektor_kolom = vektor.unsqueeze(1)
print("Vektor Kolom:\n", vektor_kolom)Output:
Vektor Kolom:
tensor([[1],
[2],
[3],
[4],
[5]])Pada contoh ini, unsqueeze(1) menambahkan dimensi kedua pada tensor, mengubah vektor satu dimensi menjadi vektor kolom dengan dimensi (5, 1).
Mengubah vektor kolom kembali ke vektor baris:
python
# Mengubah vektor kolom kembali menjadi vektor baris (tensor orde 1)
vektor_baris = vektor_kolom.squeeze(1)
print("Vektor Baris:", vektor_baris)Output:
Vektor Baris: tensor([1, 2, 3, 4, 5])Di sini, squeeze(1) menghapus dimensi kedua (kolom) dan mengembalikannya menjadi vektor satu dimensi (orde 1).
3. Vektor Nol (Zero Vector)
Vektor nol adalah vektor yang berisi semua elemen bernilai nol. Vektor nol sering digunakan dalam berbagai operasi matematika atau algoritma, seperti dalam inisialisasi bobot pada neural network.
Untuk membuat vektor nol di PyTorch, kita dapat menggunakan fungsi torch.zeros().
Contoh membuat vektor nol di PyTorch:
python
# Membuat vektor nol (tensor orde 1)
vektor_nol = torch.zeros(5)
print("Vektor Nol:", vektor_nol)Output:
Vektor Nol: tensor([0., 0., 0., 0., 0.])Pada contoh ini, kita membuat vektor nol dengan 5 elemen yang semuanya bernilai nol. torch.zeros(5) menghasilkan tensor dengan 5 elemen yang semuanya adalah nol, dan tensor ini memiliki dimensi (5,).
4. Operasi pada Vektor
Setelah memahami bagaimana membuat vektor, transposisi vektor, dan vektor nol, kita dapat melakukan berbagai operasi pada vektor, seperti penjumlahan, perkalian, dan operasi aritmatika lainnya. Berikut beberapa contoh operasi sederhana:
Penjumlahan Vektor:
python
# Penjumlahan dua vektor
vektor2 = torch.tensor([1, 1, 1, 1, 1])
hasil_penjumlahan = vektor + vektor2
print("Hasil Penjumlahan:", hasil_penjumlahan)Output:
Hasil Penjumlahan: tensor([2, 3, 4, 5, 6])Perkalian Skalar dengan Vektor:
python
# Perkalian skalar dengan vektor
hasil_perkalian = 3 * vektor
print("Hasil Perkalian Skalar:", hasil_perkalian)Output:
Hasil Perkalian Skalar: tensor([3, 6, 9, 12, 15])5. Norma
Di sini,
Beberapa poin penting tentang norm
- Sifat Euclidean.
norm dihitung dengan mengambil akar kuadrat dari jumlah kuadrat dari komponen vektor. - Representasi Geometris. Dalam ruang dua dimensi (
), norm dari vektor adalah panjang garis lurus dari titik awal ke titik akhir yang diwakili oleh vektor tersebut di dalam ruang Euclidean. - Kasus Khusus di Bidang Machine Learning.
norm sering digunakan dalam konteks pembelajaran mesin sebagai fungsi objektif atau fungsi kehilangan (loss function), terutama dalam regularisasi seperti ridge regression, di mana tujuannya adalah untuk meminimalkan norm dari parameter.
Norm
6. Norma
Norma
Untuk suatu vektor
Di sini,
Beberapa poin penting tentang norma
- Sifat Manhattan. Norma
dihitung dengan menjumlahkan nilai absolut dari perbedaan antara komponen-komponen vektor. - Representasi Geometris. Dalam ruang dua dimensi (
), norma dari vektor adalah jarak yang ditempuh jika hanya diizinkan berjalan sepanjang garis horizontal dan vertikal (seperti jalan dalam kota). - Kasus Khusus di Bidang Machine Learning. Norma
sering digunakan dalam konteks regularisasi, terutama dalam LASSO (Least Absolute Shrinkage and Selection Operator), di mana tujuannya adalah untuk meminimalkan nilai dari norma dari parameter.
Norma
7. Max Norm (Norma Maksimum)
Max Norm atau Norm Maksimum adalah salah satu jenis norma vektor yang digunakan untuk mengukur "ukuran" atau "panjang" vektor berdasarkan elemen terbesar dari vektor tersebut. Dalam konteks ini, Max Norm didefinisikan sebagai nilai absolut dari elemen terbesar dalam vektor.
Secara matematis, jika kita memiliki vektor
Di sini, kita mengambil nilai terbesar dari semua nilai absolut elemen dalam vektor. Max Norm ini dikenal juga dengan nama Infinity Norm atau L∞ Norm.
Penggunaan dalam machine learning
Max Norm sering digunakan dalam konteks pembelajaran mesin, misalnya dalam regularisasi untuk mencegah overfitting dengan membatasi nilai terbesar yang dapat dimiliki oleh elemen-elemen dari vektor, seperti bobot (weights) dalam neural network.
Contoh Max Norm di PyTorch
Kita akan membuat contoh vektor dan menghitung Max Norm dari vektor tersebut menggunakan PyTorch.
Langkah-langkah
- Membuat vektor tensor di PyTorch.
- Menghitung Max Norm (Norm Maksimum) dari vektor menggunakan
torch.abs()dantorch.max().
Contoh Implementasi:
python
import torch
# Membuat vektor tensor (orde 1)
vektor = torch.tensor([3.0, -4.0, 5.0, -2.0])
# Menghitung Max Norm (Norm Maksimum)
max_norm = torch.max(torch.abs(vektor))
print("Vektor:", vektor)
print("Max Norm (Norm Maksimum):", max_norm)Output:
Vektor: tensor([ 3., -4., 5., -2.])
Max Norm (Norm Maksimum): tensor(5.)Penjelasan:
torch.abs(vektor): Fungsi ini mengembalikan tensor baru yang berisi nilai absolut dari setiap elemen vektor.- Misalnya, dari vektor
[3, -4, 5, -2]menjadi[3, 4, 5, 2].
- Misalnya, dari vektor
torch.max(): Fungsi ini digunakan untuk mendapatkan nilai maksimum dari tensor. Di sini, kita menggunakantorch.max(torch.abs(vektor))untuk mendapatkan nilai terbesar dari nilai absolut elemen vektor.- Misalnya, dari vektor
[3, 4, 5, 2], nilai terbesar adalah5.
- Misalnya, dari vektor
Dengan demikian, Max Norm dari vektor [3, -4, 5, -2] adalah 5, yang merupakan nilai terbesar dalam nilai absolut elemen-elemen vektor tersebut.
8. Orthogonal Vectors
In [52]:
i = np.array([1, 0])
iOut[52]:
array([1, 0])In [53]:
j = np.array([0, 1])
jOut[53]:
array([0, 1])In [54]:
np.dot(i, j) # detail on the dot operation coming up...Out[54]:
0Matrik (Tensor ordo 2)
Matriks adalah struktur data yang terdiri dari elemen-elemen yang terorganisir dalam bentuk baris dan kolom. Sebuah matriks disebut tensor orde 2 karena memiliki dua dimensi: satu untuk baris dan satu lagi untuk kolom. Dalam konteks pembelajaran mesin atau komputasi numerik, matriks sering digunakan untuk merepresentasikan data seperti gambar, teks, atau fitur dari dataset.
Secara matematis, sebuah matriks
Dalam PyTorch, matriks dapat direpresentasikan sebagai tensor orde 2.
Operasi Matriks
Ada beberapa operasi dasar yang dapat dilakukan pada matriks:
Penjumlahan Matriks: Penjumlahan dua matriks yang ukurannya sama dilakukan dengan menjumlahkan elemen-elemen yang bersesuaian.
- Jika
dan adalah dua matriks dengan ukuran yang sama, maka hasil penjumlahan .
- Jika
Perkalian Matriks: Matriks
dapat dikalikan dengan matriks jika jumlah kolom pada sama dengan jumlah baris pada . - Hasil dari perkalian dua matriks
dan , yang diwakili oleh , adalah matriks baru dengan dimensi baris dari dan kolom dari .
- Hasil dari perkalian dua matriks
Transpose Matriks: Transposisi dari matriks
diperoleh dengan menukar baris dan kolomnya. adalah matriks yang diperoleh dengan transposisi matriks .
Invers Matriks: Matriks
memiliki invers, yang ditulis sebagai , jika dan hanya jika matriks tersebut adalah matriks persegi dan tidak singular (determinannya tidak nol). Matriks invers digunakan untuk menyelesaikan sistem persamaan linear. Perkalian Skalar Matriks: Matriks dapat dikalikan dengan skalar (angka), yang berarti setiap elemen matriks dikalikan dengan angka tersebut.
Contoh Matriks dan Operasi Matriks di PyTorch
1. Membuat Matriks (Tensor Orde 2)
Kita dapat membuat matriks menggunakan torch.tensor() atau dengan fungsi-fungsi lainnya seperti torch.ones(), torch.zeros(), dll.
python
import torch
# Membuat matriks 3x3
A = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=torch.float32)
B = torch.tensor([[9, 8, 7], [6, 5, 4], [3, 2, 1]], dtype=torch.float32)
print("Matriks A:\n", A)
print("\nMatriks B:\n", B)Output:
Matriks A:
tensor([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
Matriks B:
tensor([[9., 8., 7.],
[6., 5., 4.],
[3., 2., 1.]])2. Penjumlahan Matriks
Penjumlahan dua matriks $ A $ dan $ B $ dengan dimensi yang sama dapat dilakukan dengan operator +.
python
# Penjumlahan matriks
C = A + B
print("Hasil Penjumlahan A dan B:\n", C)Output:
Hasil Penjumlahan A dan B:
tensor([[10., 10., 10.],
[10., 10., 10.],
[10., 10., 10.]])3. Perkalian Matriks
Perkalian matriks dapat dilakukan dengan operator @ atau dengan fungsi torch.matmul().
python
# Perkalian Matriks
D = torch.matmul(A, B) # Matriks hasil perkalian A dan B
print("Hasil Perkalian Matriks A dan B:\n", D)Output:
Hasil Perkalian Matriks A dan B:
tensor([[30., 24., 18.],
[84., 69., 54.],
[138., 114., 90.]])4. Transpose Matriks
Untuk melakukan transposisi pada matriks, kita dapat menggunakan fungsi torch.T atau A.transpose().
python
# Transpose Matriks
A_T = A.T
print("Transpose Matriks A:\n", A_T)Output:
Transpose Matriks A:
tensor([[1., 4., 7.],
[2., 5., 8.],
[3., 6., 9.]])5. Perkalian Skalar Matriks
Perkalian skalar dilakukan dengan mengalikan matriks dengan sebuah angka (skalar).
python
# Perkalian Matriks dengan Skalar
E = 2 * A # Matriks A dikalikan dengan 2
print("Hasil Perkalian Matriks A dengan Skalar 2:\n", E)Output:
Hasil Perkalian Matriks A dengan Skalar 2:
tensor([[2., 4., 6.],
[8., 10., 12.],
[14., 16., 18.]])6. Invers Matriks
Untuk menghitung invers matriks, kita bisa menggunakan fungsi torch.inverse() untuk matriks persegi.
python
# Membuat matriks persegi 2x2 untuk menghitung invers
F = torch.tensor([[1.0, 2.0], [3.0, 4.0]], dtype=torch.float32)
# Menghitung invers matriks
F_inv = torch.inverse(F)
print("Invers Matriks F:\n", F_inv)Output:
Invers Matriks F:
tensor([[-2.0000, 1.0000],
[ 1.5000, -0.5000]])Tensor Ordo Tinggi
Tensor Ordo Tinggi (Rank 4 Tensors)
Tensor ordo tinggi, seperti rank 4 tensor, adalah tensor dengan empat dimensi. Dalam konteks pembelajaran mesin dan pengolahan gambar, tensor dengan ordo tinggi sering digunakan untuk merepresentasikan data gambar.
Sebagai contoh, pada dataset gambar seperti MNIST atau CIFAR-10, gambar-gambar tersebut biasanya disimpan dalam tensor dengan rank 4 yang menyimpan beberapa informasi penting dalam empat dimensi tersebut.
Dimensi-Dimensi dalam Rank 4 Tensor:
Batch Size (Jumlah Gambar dalam Satu Batch):
- Dimensi pertama dalam tensor atau rank 4 adalah jumlah gambar yang ada dalam satu batch.
- Misalnya, dalam satu batch pelatihan, kita memiliki 32 gambar, sehingga dimensi pertama adalah 32.
Tinggi Gambar (Height of Image):
- Dimensi kedua menunjukkan tinggi gambar dalam piksel.
- Misalnya, pada dataset MNIST yang terdiri dari gambar digit berukuran 28x28 piksel, dimensi kedua adalah 28.
Lebar Gambar (Width of Image):
- Dimensi ketiga menunjukkan lebar gambar dalam piksel.
- Misalnya, untuk gambar MNIST yang memiliki ukuran 28x28 piksel, dimensi ketiga juga adalah 28.
Jumlah Saluran Warna (Number of Color Channels):
- Dimensi keempat menunjukkan jumlah saluran warna (channels) pada gambar.
- Gambar berwarna penuh biasanya memiliki 3 saluran warna (RGB: Merah, Hijau, Biru), sedangkan gambar hitam-putih memiliki 1 saluran warna.
- Sebagai contoh, untuk gambar warna RGB, dimensi keempat adalah 3.
Contoh Tensor Ordo Tinggi pada Gambar RGB (Batch of Images)
Misalkan kita memiliki sebuah batch gambar dengan ukuran 32 gambar, di mana masing-masing gambar berukuran 28x28 piksel dan memiliki 3 saluran warna (RGB). Maka tensor yang merepresentasikan batch ini akan memiliki dimensi $ (32, 28, 28, 3) $, yang dapat dijelaskan sebagai:
- 32: Jumlah gambar dalam batch.
- 28: Tinggi gambar dalam piksel.
- 28: Lebar gambar dalam piksel.
- 3: Jumlah saluran warna (RGB).
Representasi Matematis Tensor Rank 4
Di sini, T merepresentasikan tensor yang berisi nilai untuk tiap piksel dan saluran warna pada setiap gambar dalam batch.
Contoh Penggunaan Tensor Ordo Tinggi dalam PyTorch
Pada PyTorch, tensor dengan rank 4 ini sering digunakan untuk merepresentasikan gambar dalam deep learning. Berikut adalah contoh pembuatan tensor rank 4 untuk dataset gambar.
python
import torch
# Misalkan kita memiliki 32 gambar, masing-masing berukuran 28x28 piksel, dengan 3 saluran warna (RGB)
batch_size = 32
height = 28
width = 28
channels = 3
# Membuat tensor dengan dimensi (32, 28, 28, 3) yang berisi angka acak
images_tensor = torch.randn(batch_size, height, width, channels)
# Menampilkan dimensi tensor
print("Dimensi tensor batch gambar: ", images_tensor.shape)Output:
Dimensi tensor batch gambar: torch.Size([32, 28, 28, 3])Penjelasan Kode
torch.randn(batch_size, height, width, channels)membuat tensor dengan dimensi yang sesuai dengan batch gambar. Nilai dalam tensor ini diisi dengan angka acak yang terdistribusi normal (Gaussian).- Tensor ini memiliki dimensi (32, 28, 28, 3), yang berarti 32 gambar, masing-masing berukuran 28x28 piksel, dengan 3 saluran warna (RGB).
Mengapa Tensor Ordo 4 Diperlukan?
Tensor ordo 4 sangat penting dalam pemrosesan gambar karena banyaknya gambar yang digunakan dalam satu batch, serta banyaknya dimensi yang diperlukan untuk mewakili informasi spasial (tinggi dan lebar gambar) dan warna (saluran RGB).
Dengan tensor ordo tinggi ini, kita dapat melakukan operasi seperti pelatihan jaringan saraf, konvolusi, dan berbagai transformasi lainnya dalam deep learning, terutama dalam bidang pengolahan citra.
Tensor Transposition
Tensor Transposition adalah operasi yang mengubah urutan dimensi suatu tensor. Pada tensor dengan lebih dari satu dimensi, transposisi dapat mengubah susunan dimensi tersebut, sama seperti transposisi matriks yang mengubah baris menjadi kolom dan kolom menjadi baris.
Dalam hal tensor dengan lebih dari dua dimensi, transposisi dapat dilakukan dengan memilih dimensi mana yang akan dipertukarkan. Hal ini bisa sangat berguna dalam berbagai konteks, seperti manipulasi data dalam deep learning atau ketika kita ingin memanipulasi data tensor dengan cara yang lebih fleksibel.
Transposisi pada Tensor 2D (Matriks)
Pada tensor ordo 2 (matriks), transposisi berfungsi dengan cara yang sama seperti yang kita ketahui dalam aljabar linier: mengubah baris menjadi kolom dan kolom menjadi baris.
Jika kita memiliki matriks
Contoh transposisi matriks
Transposisi pada Tensor Ordo Tinggi
Untuk tensor dengan lebih dari dua dimensi, kita bisa melakukan transposisi dengan memilih dua dimensi untuk dipertukarkan. Misalnya, pada tensor ordo 3, transposisi dapat dilakukan dengan menukar dua dimensi dari tensor tersebut.
Sebagai contoh, jika kita memiliki tensor ordo 3 yang memiliki dimensi $ (d_1, d_2, d_3) $, kita dapat mentranspose dimensi
Transposisi dengan PyTorch
Pada PyTorch, operasi transposisi dapat dilakukan dengan fungsi torch.transpose() atau tensor.T untuk matriks (tensor ordo 2). Untuk tensor ordo lebih tinggi, kita dapat menggunakan torch.permute() untuk memilih dimensi yang akan dipertukarkan.
Contoh Transposisi pada Tensor Ordo 2 (Matriks)
python
import torch
# Membuat tensor 2D (matriks)
tensor_2d = torch.tensor([[1, 2, 3],
[4, 5, 6]])
# Melakukan transposisi
tensor_2d_transpose = tensor_2d.T
print("Tensor asli:")
print(tensor_2d)
print("\nTensor setelah transposisi:")
print(tensor_2d_transpose)Output:
Tensor asli:
tensor([[1, 2, 3],
[4, 5, 6]])
Tensor setelah transposisi:
tensor([[1, 4],
[2, 5],
[3, 6]])Pada contoh di atas, kita menggunakan tensor_2d.T untuk melakukan transposisi pada tensor ordo 2 (matriks). Fungsi T adalah cara yang sederhana untuk mentranspose tensor ordo 2.
Contoh Transposisi pada Tensor Ordo 3
Pada tensor ordo 3, kita bisa menggunakan torch.permute() untuk mengubah urutan dimensi tensor. Misalnya, jika kita memiliki tensor dengan dimensi $ (d_1, d_2, d_3) $, kita bisa mentransposenya menjadi $ (d_2, d_1, d_3) $ dengan menukar dimensi pertama dan kedua.
python
# Membuat tensor ordo 3
tensor_3d = torch.tensor([[[1, 2], [3, 4]],
[[5, 6], [7, 8]]])
# Melakukan transposisi dengan permute
tensor_3d_transpose = tensor_3d.permute(1, 0, 2)
print("Tensor asli:")
print(tensor_3d)
print("\nTensor setelah transposisi:")
print(tensor_3d_transpose)Output:
Tensor asli:
tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
Tensor setelah transposisi:
tensor([[[1, 2],
[5, 6]],
[[3, 4],
[7, 8]]])Pada contoh di atas, kita menggunakan tensor_3d.permute(1, 0, 2) untuk mentranspose tensor ordo 3, di mana dimensi pertama dan kedua ditukar.
Fungsi torch.permute() digunakan untuk merubah urutan dimensi dari tensor. Fungsi ini mengambil parameter yang merupakan urutan indeks dimensi yang diinginkan. Sebagai contoh, pada tensor ordo 3 dengan dimensi $ (d_1, d_2, d_3) $, kita bisa mengubah urutannya menjadi $ (d_2, d_1, d_3) $, atau dimensi lainnya sesuai dengan kebutuhan.
Properti Aritmatika Dasar pada Tensor
Tensor, sebagai objek matematika, memiliki properti dasar tertentu saat melakukan operasi seperti penjumlahan atau perkalian. Operasi ini dapat diterapkan secara elemen-per-elemen, yang berarti operasi dilakukan pada setiap elemen tensor secara individual. Properti-properti ini sangat penting ketika bekerja dengan tensor di dalam framework seperti PyTorch atau TensorFlow, terutama dalam pembelajaran mesin di mana operasi tensor digunakan secara luas.
1. Operasi Skalar pada Tensor
Ketika kita menambahkan atau mengalikan sebuah skalar dengan tensor, operasi tersebut diterapkan secara elemen-per-elemen pada setiap elemen tensor. Bentuk tensor tetap tidak berubah setelah operasi ini, karena skalar hanya berinteraksi dengan setiap elemen secara terpisah dan tidak mempengaruhi struktur keseluruhan tensor.
Penjumlahan Skalar dengan Tensor
Ketika sebuah skalar ditambahkan ke tensor, setiap elemen tensor akan dijumlahkan dengan skalar tersebut. Operasi ini dilakukan elemen-per-elemen.
Misalnya, jika kita memiliki tensor
Jika kita menambahkan skalar 2 ke tensor tersebut, hasilnya adalah:
Perkalian Skalar dengan Tensor
Begitu juga, ketika sebuah skalar dikalikan dengan tensor, setiap elemen tensor akan dikalikan dengan skalar tersebut. Operasi ini juga dilakukan elemen-per-elemen.
Misalnya, jika kita memiliki tensor
2. Perkalian Elemen-per-Elemen (Hadamard Product)
Pada perkalian elemen-per-elemen, yang sering disebut Hadamard Product, operasi perkalian dilakukan pada setiap elemen tensor secara terpisah, tanpa memperhatikan struktur dimensi tensor secara keseluruhan. Artinya, setiap elemen tensor
Misalnya, kita memiliki dua tensor
Maka, hasil perkalian Hadamard antara
3. Bentuk Tensor Tidak Berubah
Setelah melakukan operasi penjumlahan atau perkalian dengan skalar, bentuk (shape) tensor tetap sama. Artinya, jumlah dimensi dan ukuran setiap dimensi tensor tidak berubah. Hanya nilai elemen tensor yang diubah sesuai dengan operasi yang diterapkan.
Sebagai contoh, jika kita memiliki tensor
Contoh Penggunaan di PyTorch
python
import torch
# Membuat tensor 2D
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
# Penjumlahan tensor dengan skalar
tensor_plus_2 = tensor + 2
# Perkalian tensor dengan skalar
tensor_times_3 = tensor * 3
print("Tensor asli:")
print(tensor)
print("\nTensor setelah penjumlahan dengan 2:")
print(tensor_plus_2)
print("\nTensor setelah perkalian dengan 3:")
print(tensor_times_3)Output:
Tensor asli:
tensor([[1, 2, 3],
[4, 5, 6]])
Tensor setelah penjumlahan dengan 2:
tensor([[3, 4, 5],
[6, 7, 8]])
Tensor setelah perkalian dengan 3:
tensor([[ 3, 6, 9],
[12, 15, 18]])Operasi ini adalah dasar dalam pemrosesan data tensor di machine learning dan sangat berguna untuk manipulasi dan transformasi data dalam model.
Reduction pada Tensor
Reduction merujuk pada proses pengurangan dimensi tensor melalui operasi seperti penjumlahan atau operasi lainnya yang mengurangi tensor menjadi nilai yang lebih sederhana, berdasarkan operasi tertentu. Salah satu operasi yang paling umum dalam konteks reduction adalah penjumlahan seluruh elemen dalam tensor, tetapi dapat juga mencakup operasi lainnya seperti rata-rata, maksimum, atau minimumnya.
Misalnya, kita dapat menghitung jumlah seluruh elemen pada sebuah tensor (seperti vektor atau matriks), yang biasanya digunakan untuk mendapatkan total atau agregat dari data yang ada.
Contoh Pengurangan Dimensi dengan Penjumlahan
Untuk Vektor (Tensor Orde 1) Misalkan kita memiliki vektor
yang terdiri dari elemen-elemen . Penjumlahan seluruh elemen vektor ini adalah: Dimana
adalah panjang vektor . Penjumlahan ini menghasilkan nilai tunggal yang mewakili total seluruh elemen pada vektor. Untuk Matriks (Tensor Orde 2) Jika kita memiliki matriks
berukuran dengan elemen-elemen , penjumlahan seluruh elemen dalam matriks dapat dihitung dengan: Dimana
adalah jumlah baris dan adalah jumlah kolom matriks. Dengan penjumlahan ini, kita menggabungkan seluruh nilai dalam matriks menjadi satu angka yang mewakili jumlah total elemen matriks.
Reduction dalam PyTorch
Pada PyTorch, kita bisa melakukan operasi reduction ini dengan menggunakan berbagai fungsi built-in seperti torch.sum(), torch.mean(), dan lain-lain. Misalnya:
Penjumlahan seluruh elemen dalam tensor (Reduction)
Untuk Vektor (Tensor Orde 1) Kita dapat menghitung jumlah seluruh elemen dalam vektor menggunakan
torch.sum().pythonimport torch # Membuat tensor vektor x = torch.tensor([1, 2, 3, 4, 5]) # Menghitung jumlah seluruh elemen total_sum = torch.sum(x) print("Jumlah seluruh elemen vektor:", total_sum)Output:
Jumlah seluruh elemen vektor: tensor(15)
Penjumlahan seluruh elemen dalam Matriks (Tensor Orde 2)
Untuk Matriks (Tensor Orde 2) Kita dapat menghitung jumlah seluruh elemen dalam matriks menggunakan
torch.sum()dengan menghilangkan dimensi tertentu, atau langsung menghitung seluruh elemen.python# Membuat tensor matriks X = torch.tensor([[1, 2, 3], [4, 5, 6]]) # Menghitung jumlah seluruh elemen total_sum_matrix = torch.sum(X) print("Jumlah seluruh elemen matriks:", total_sum_matrix)Output:
Jumlah seluruh elemen matriks: tensor(21)
Reduction berdasarkan dimensi tertentu
Anda juga bisa melakukan reduction berdasarkan dimensi tertentu untuk menghasilkan hasil penjumlahan yang lebih terbatas pada dimensi tersebut.
Penjumlahan berdasarkan baris (dimensi 0) Kita dapat menghitung penjumlahan seluruh elemen dalam setiap baris (kolomnya akan hilang).
python# Penjumlahan berdasarkan baris sum_rows = torch.sum(X, dim=1) print("Penjumlahan berdasarkan baris:", sum_rows)Output:
Penjumlahan berdasarkan baris: tensor([ 6, 15])Penjumlahan berdasarkan kolom (dimensi 1) Anda bisa menghitung penjumlahan berdasarkan kolom.
python# Penjumlahan berdasarkan kolom sum_columns = torch.sum(X, dim=0) print("Penjumlahan berdasarkan kolom:", sum_columns)Output:
Penjumlahan berdasarkan kolom: tensor([5, 7, 9])
Penggunaan Reduction Lainnya
Selain penjumlahan, Anda bisa melakukan operasi reduction lainnya seperti:
- Rata-rata elemen menggunakan
torch.mean() - Maksimum elemen menggunakan
torch.max() - Minimum elemen menggunakan
torch.min() - Norma (seperti L2-norm) menggunakan
torch.norm()
Berikut adalah contoh penghitungan rata-rata elemen dalam tensor:
python
# Rata-rata seluruh elemen
mean_value = torch.mean(X.float()) # Harus konversi ke float karena rata-rata bukan integer
print("Rata-rata seluruh elemen matriks:", mean_value)Output:
Rata-rata seluruh elemen matriks: tensor(3.5000)The Dot Product (Produk Titik)
Produk titik atau dot product adalah operasi matematika yang menggabungkan dua vektor menjadi satu nilai skalar. Operasi ini sangat penting dalam berbagai aplikasi, terutama dalam aljabar linear, machine learning, dan grafik komputer.
Untuk dua vektor
Definisi Matematis
Jika
Atau, dalam bentuk lainnya:
, yang merupakan hasil perkalian antara transpos dari vektor dengan vektor . , yang menyatakan dot product sebagai produk skalar antara dua vektor.
Interpretasi
- Produk titik menghasilkan nilai skalar, bukan vektor.
- Dot product mengukur seberapa "sejajar" dua vektor. Jika vektor-vektor tersebut lebih sejajar, produk titik mereka akan lebih besar.
- Jika dua vektor ortogonal (mempunyai sudut 90 derajat), maka dot product mereka adalah 0.
- Jika produk titiknya positif, vektor tersebut memiliki arah yang mirip, jika negatif, arah mereka berlawanan.
Contoh dalam PyTorch:
Di PyTorch, Anda bisa menghitung dot product dengan menggunakan fungsi torch.dot() atau operator @ untuk dua vektor 1D.
Berikut adalah contoh penerapan dot product di PyTorch:
python
import torch
# Membuat dua tensor (vektor)
x = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
# Menghitung dot product menggunakan torch.dot()
dot_product = torch.dot(x, y)
print("Dot product antara x dan y:", dot_product)Output:
Dot product antara x dan y: tensor(32)Penjelasan
- Dalam contoh di atas, vektor
dan . - Dot product dihitung sebagai:
Pentingnya Dot Product
- Pengukuran kesamaan vektor. Dot product sering digunakan untuk mengukur kesamaan antara dua vektor. Dalam machine learning, ini banyak digunakan dalam algoritma seperti regresi linier, support vector machines (SVM), atau jaringan saraf tiruan.
- Proyeksi vektor: Dot product juga digunakan untuk menghitung panjang proyeksi satu vektor ke vektor lainnya.
- Kalkulasi sudut antara vektor: Jika dot product dibagi dengan norma dari kedua vektor, kita bisa memperoleh nilai cosine dari sudut antara dua vektor, yang sering digunakan dalam pengukuran kesamaan teks atau gambar.
Dot Product dalam Higher Dimensional Tensors
Selain vektor 1D, produk titik juga dapat diperluas untuk tensor dengan dimensi lebih tinggi, misalnya untuk matriks (tensor orde-2) atau tensor lebih tinggi. Untuk matriks, produk titik biasanya disebut produk matriks, dan di PyTorch, fungsi seperti torch.matmul() atau operator @ bisa digunakan untuk menghitung produk matriks.
Penting!
- Produk titik antara dua vektor mengukur hubungan antara keduanya dan menghasilkan sebuah nilai skalar.
- Dalam notasi, produk titik bisa ditulis sebagai
, , atau . - Di PyTorch, produk titik dapat dihitung menggunakan
torch.dot()atau operator@untuk dua vektor 1D.
Penyelesaian Sistem Linear: Teknik Substitusi dan Eliminasi
Sistem persamaan linear adalah sekumpulan persamaan linear yang mengandung dua atau lebih variabel. Dalam matematika, tujuan kita adalah menemukan nilai variabel yang memenuhi semua persamaan dalam sistem tersebut.
Secara umum, sistem persamaan linear dapat dinyatakan dalam bentuk matriks sebagai berikut:
di mana:
adalah matriks koefisien (biasanya berbentuk matriks ), adalah vektor yang berisi variabel yang ingin dicari, adalah vektor hasil dari setiap persamaan.
Terdapat beberapa metode untuk menyelesaikan sistem persamaan linear, yang paling umum adalah metode substitusi dan metode eliminasi.
1. Teknik Substitusi
Metode substitusi adalah teknik di mana kita menyelesaikan salah satu persamaan untuk satu variabel, kemudian menggantikan variabel tersebut dalam persamaan lainnya.
Langkah-langkah Substitusi
- Pilih salah satu persamaan dalam sistem dan selesaikan untuk salah satu variabel.
- Substitusikan hasil dari variabel yang sudah diselesaikan ke dalam persamaan lainnya.
- Ulangi langkah ini untuk variabel yang tersisa sampai semua variabel ditemukan.
Contoh:
Sistem persamaan linear:
- Dari persamaan (1), kita selesaikan untuk
:
- Substitusikan nilai
ke dalam persamaan (2):
- Setelah menemukan nilai
, kita substitusikan ke dalam persamaan (1):
Jadi, solusi dari sistem persamaan ini adalah
2. Teknik Eliminasi (Metode Eliminasi Gauss)
Metode eliminasi, juga dikenal dengan Metode Gauss, adalah teknik yang digunakan untuk menghilangkan satu variabel dengan cara menambahkan atau mengurangkan persamaan sehingga satu variabel hilang. Kemudian, kita menyelesaikan sistem persamaan yang lebih sederhana.
Langkah-langkah Eliminasi
- Tulis sistem persamaan dalam bentuk standar.
- Kalikan persamaan jika diperlukan untuk membuat koefisien variabel yang sama.
- Tambahkan atau kurangkan persamaan untuk mengeliminasi satu variabel.
- Selesaikan untuk variabel yang tersisa.
- Substitusikan nilai yang ditemukan ke dalam persamaan lainnya untuk menemukan nilai variabel lainnya.
Contoh:
Sistem persamaan linear:
Untuk mengeliminasi
, kita kalikan persamaan (1) dengan 1 dan persamaan (2) dengan 1: - Persamaan (1) tetap
- Persamaan (2) tetap
- Persamaan (1) tetap
Jumlahkan kedua persamaan untuk mengeliminasi
:
- Setelah menemukan nilai
, substitusikan ke dalam salah satu persamaan, misalnya (1):
Jadi, solusi dari sistem ini adalah
Perbandingan Antara Substitusi dan Eliminasi
- Substitusi lebih berguna ketika salah satu variabel dapat dengan mudah diisolasi dalam persamaan, sementara eliminasi lebih efisien saat koefisien variabel lebih mudah disesuaikan atau jika ada banyak variabel.
- Eliminasi cenderung lebih cepat ketika bekerja dengan sistem persamaan linear dengan lebih dari dua variabel.
- Kedua metode ini akan memberikan hasil yang sama, tetapi pilihan metode tergantung pada kompleksitas sistem persamaan yang diberikan.
Contoh Implementasi dengan PyTorch
PyTorch dapat digunakan untuk menyelesaikan sistem persamaan linear menggunakan fungsi tensor. Berikut adalah contoh implementasi solusi sistem persamaan linear menggunakan Metode Eliminasi Gauss di PyTorch.
python
import torch
# Matriks koefisien A (2x2) dan vektor hasil b (2x1)
A = torch.tensor([[1., 1.], [2., -1.]])
b = torch.tensor([5., 1.])
# Menggunakan PyTorch untuk menyelesaikan sistem persamaan linear
x = torch.linalg.solve(A, b)
print("Solusi x dan y:", x)Penjelasan:
- Matriks $A $ adalah matriks koefisien sistem persamaan.
- Vektor
adalah hasil dari setiap persamaan. - Fungsi
torch.linalg.solve()digunakan untuk menyelesaikan sistem persamaan linear.
Properti-properti Matrik
Frobenius Norm**
Norma Frobenius adalah salah satu jenis norma yang digunakan untuk mengukur ukuran atau "besar" dari sebuah matriks. Ini adalah bentuk norma matriks yang paling umum dan mudah dihitung. Norma Frobenius dihitung dengan cara yang mirip dengan menghitung panjang atau magnitude dari sebuah vektor, tetapi untuk matriks.
Definisi Frobenius Norm
Norma Frobenius dari matriks
di mana:
adalah elemen pada baris ke- dan kolom ke- dari matriks , adalah nilai absolut dari elemen , - Penjumlahan dilakukan untuk seluruh elemen matriks
.
Secara sederhana, norma Frobenius mengukur seberapa besar matriks tersebut dengan cara menjumlahkan kuadrat dari semua elemen, kemudian mengambil akar kuadrat dari jumlah tersebut.
Interpretasi Norma Frobenius
Norma Frobenius dapat dianggap sebagai ukuran total "besar" dari matriks, yang menunjukkan seberapa banyak energi yang dikandung oleh matriks tersebut dalam bentuk elemen-elemen individualnya. Semakin besar nilai norma Frobenius, semakin besar elemen-elemen dalam matriks.
Sebagai contoh, jika matriks berisi banyak elemen besar, maka norma Frobenius akan menjadi lebih besar. Sebaliknya, jika elemen-elemen matriks kecil, norma Frobenius juga akan kecil.
Contoh Penghitungan Norma Frobenius
Misalkan kita memiliki matriks
Norma Frobenius dari matriks
Jadi, norma Frobenius dari matriks
Penggunaan dalam Machine Learning dan Deep Learning
Norma Frobenius sering digunakan dalam berbagai aplikasi dalam machine learning, khususnya dalam optimasi dan pembelajaran mesin. Beberapa contohnya adalah:
Regularisasi Matriks. Dalam metode pembelajaran mesin, norma Frobenius dapat digunakan sebagai bagian dari regularisasi untuk mencegah overfitting. Regularisasi ini dapat membantu mengontrol besar elemen-elemen dalam matriks, seperti dalam kasus pembelajaran dengan matriks bobot dalam jaringan saraf.
Perbandingan Matriks. Norma Frobenius dapat digunakan untuk membandingkan dua matriks, misalnya untuk mengukur seberapa besar perbedaan antara dua matriks yang dihasilkan selama proses pelatihan.
Penyelesaian Masalah Optimasi. Dalam metode optimasi, norma Frobenius sering digunakan untuk mengukur ukuran dari gradien atau error matriks.
Contoh Penggunaan Norma Frobenius di PyTorch
Di PyTorch, kita dapat menghitung norma Frobenius dari matriks menggunakan fungsi torch.norm() dengan parameter p='fro'. Berikut adalah contoh penggunaannya:
python
import torch
# Membuat sebuah matriks
A = torch.tensor([[1., 2.], [3., 4.]])
# Menghitung norma Frobenius
frobenius_norm = torch.norm(A, p='fro')
print("Norma Frobenius dari A:", frobenius_norm)Penjelasan:
torch.tensordigunakan untuk membuat matriks. torch.norm(A, p='fro')menghitung norma Frobenius dari matriks. - Hasilnya akan menunjukkan nilai akar kuadrat dari jumlah kuadrat elemen-elemen matriks.
Perkalian Matriks dengan Vektor
Perkalian matriks dengan vektor adalah operasi matematika yang melibatkan matriks dan vektor. Ini sangat umum digunakan dalam berbagai aplikasi, terutama dalam machine learning, terutama dalam operasi linear dan transformasi.
Langkah-langkah Perkalian Matriks dengan Vektor
Misalkan kita memiliki matriks
Jika
Contoh dengan NumPy
Matriks
dan vektor didefinisikan sebagai berikut: pythonimport numpy as np A = np.array([[3, 4], [5, 6], [7, 8]]) # Matriks A berukuran 3x2 b = np.array([1, 2]) # Vektor b berukuran 2 print(A) # Output: [[3 4], [5 6], [7 8]] print(b) # Output: [1 2]Perkalian matriks dengan vektor dilakukan menggunakan
np.dot(A, b):pythonresult = np.dot(A, b) # Operasi perkalian matriks A dengan vektor b print(result) # Output: [11 17 23]Hasil perkaliannya adalah vektor
, yang didapat dengan menjumlahkan produk elemen baris matriks dengan vektor .
Contoh dengan PyTorch
Matriks
dan vektor didefinisikan sebagai tensor PyTorch: pythonimport torch A_pt = torch.tensor([[3, 4], [5, 6], [7, 8]]) # Matriks A berukuran 3x2 b_pt = torch.tensor([1, 2]) # Vektor b berukuran 2 print(A_pt) # Output: tensor([[3, 4], [5, 6], [7, 8]]) print(b_pt) # Output: tensor([1, 2])Perkalian matriks dengan vektor menggunakan
torch.matmul(A_pt, b_pt):pythonresult_pt = torch.matmul(A_pt, b_pt) # Operasi perkalian matriks dengan vektor print(result_pt) # Output: tensor([11, 17, 23])Sama seperti di NumPy, hasil perkaliannya adalah tensor
.
Contoh dengan TensorFlow
Matriks
dan vektor didefinisikan sebagai variabel TensorFlow: pythonimport tensorflow as tf A_tf = tf.Variable([[3, 4], [5, 6], [7, 8]]) # Matriks A berukuran 3x2 b_tf = tf.Variable([1, 2]) # Vektor b berukuran 2 print(A_tf) # Output: <tf.Variable 'Variable:0' shape=(3, 2) dtype=int32> print(b_tf) # Output: <tf.Variable 'Variable:0' shape=(2,) dtype=int32>Perkalian matriks dengan vektor menggunakan
tf.linalg.matvec(A_tf, b_tf):pythonresult_tf = tf.linalg.matvec(A_tf, b_tf) # Operasi perkalian matriks dengan vektor print(result_tf) # Output: tf.Tensor([11 17 23], shape=(3,), dtype=int32)Hasilnya adalah tensor
dalam TensorFlow.
Perkalian Dua Matriks
Perkalian dua matriks adalah operasi di mana setiap elemen dalam hasil matriks diperoleh dari perkalian elemen-elemen baris dari matriks pertama dengan elemen-elemen kolom dari matriks kedua dan kemudian dijumlahkan.
Jika kita memiliki dua matriks
Langkah-langkah Perkalian Matriks
Misalkan kita memiliki matriks
Dengan kata lain, elemen
Contoh dengan NumPy:
Matriks
dan didefinisikan sebagai berikut: pythonimport numpy as np A = np.array([[3, 4], [5, 6], [7, 8]]) # Matriks A berukuran 3x2 B = np.array([[1, 9], [2, 0]]) # Matriks B berukuran 2x2 print(A) # Output: [[3 4], [5 6], [7 8]] print(B) # Output: [[1 9], [2 0]]Perkalian matriks dilakukan menggunakan
np.dot(A, B)atau operator@:pythonresult = np.dot(A, B) # Operasi perkalian matriks A dan B print(result) # Output: [[11 27], [17 45], [23 63]]Hasil perkalian matriks
dan adalah matriks baru dengan elemen-elemen sebagai berikut:
Penjelasan Hasil
Untuk elemen pertama
dihitung sebagai: Untuk elemen kedua
dihitung sebagai: Untuk elemen ketiga
dihitung sebagai: Untuk elemen keempat
dihitung sebagai: Untuk elemen kelima
dihitung sebagai: Untuk elemen keenam
dihitung sebagai:
Matriks Simetris
Matriks simetris adalah matriks yang memiliki properti khusus, yaitu elemen-elemen di atas diagonal utama sama dengan elemen-elemen yang berada di bawah diagonal utama. Secara matematis, matriks
Di mana
Contoh Matriks Simetris
Misalkan kita memiliki matriks
python
import numpy as np
X_sym = np.array([[0, 1, 2], [1, 7, 8], [2, 8, 9]])
print(X_sym)Output:
Transpos Matriks
Transpos dari matriks
python
X_sym_T = X_sym.T
print(X_sym_T)Output:
Kita dapat melihat bahwa
Memeriksa Matriks Simetris
Untuk memeriksa apakah matriks
python
print(X_sym.T == X_sym)Output:
Karena semua elemen dalam hasil perbandingan adalah True, kita dapat menyimpulkan bahwa matriks
Matriks Identitas
Matriks identitas adalah matriks persegi (jumlah baris sama dengan jumlah kolom) yang memiliki elemen-elemen utama yang bernilai 1, sementara elemen-elemen lainnya bernilai 0. Matriks identitas untuk ukuran
Dalam konteks perkalian matriks, matriks identitas bertindak seperti angka
Contoh Matriks Identitas
Misalkan kita memiliki matriks identitas
python
import torch
I = torch.tensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]])
print(I)Output:
Perkalian Matriks Identitas dengan Vektor
Sekarang, mari kita coba mengalikan matriks identitas
python
x_pt = torch.tensor([25, 2, 5])
print(x_pt)Output:
Ketika kita mengalikan matriks identitas
python
result = torch.matmul(I, x_pt)
print(result)Output:
Penjelasan
Perkalian antara matriks identitas dan vektor
Invers Matriks
Invers matriks adalah suatu konsep dalam aljabar linear yang sangat penting. Jika kita memiliki suatu matriks
Dengan kata lain, invers matriks membalikkan pengaruh matriks tersebut.
Proses Menghitung Invers Matriks
Salah satu cara untuk menghitung invers matriks adalah dengan menggunakan metode np.linalg.inv() di NumPy atau fungsi serupa di PyTorch dan TensorFlow.
Contoh Matriks dan Inversnya dengan NumPy
Misalkan kita memiliki matriks
python
import numpy as np
X = np.array([[4, 2], [-5, -3]])
print(X)Matriks
Untuk menghitung invers matriks np.linalg.inv():
python
Xinv = np.linalg.inv(X)
print(Xinv)Outputnya adalah:
Membuktikan bahwa
Sekarang kita akan memverifikasi apakah hasil perkalian antara
python
np.dot(Xinv, X)Hasilnya adalah:
Hasil ini mendekati matriks identitas
Solusi Sistem Persamaan Linear
Jika kita memiliki sistem persamaan linear yang dituliskan dalam bentuk
python
y = np.array([4, -7])
print(y)Output:
Untuk menemukan
python
w = np.dot(Xinv, y)
print(w)Hasilnya adalah:
Kemudian, untuk memverifikasi bahwa solusi
python
np.dot(X, w)Hasilnya:
Ini menunjukkan bahwa
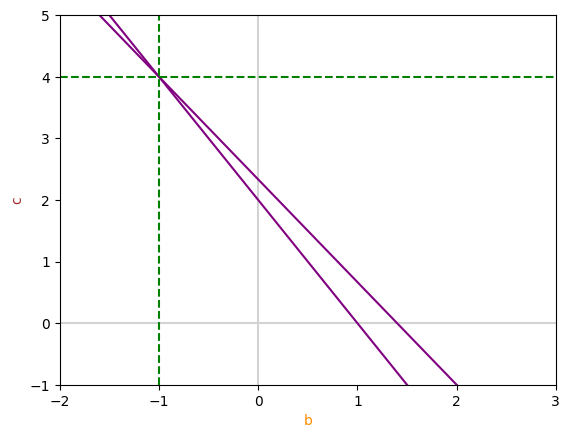
Visualisasi Geometris
Sistem persamaan linear yang kita selesaikan dapat divisualisasikan dalam bentuk dua garis. Setiap persamaan dalam sistem dapat dipandang sebagai garis dalam ruang dua dimensi, dan titik potong kedua garis tersebut adalah solusi dari sistem persamaan tersebut. Misalnya, dua persamaan berikut:
Dapat direpresentasikan sebagai dua garis dalam plot. Setelah menyelesaikan sistem ini, kita menemukan titik potong di
Visualisasi:
Menghitung Invers di PyTorch dan TensorFlow
Di PyTorch dan TensorFlow, kita juga bisa menghitung invers matriks menggunakan fungsi torch.inverse() dan tf.linalg.inv().
Contoh di PyTorch:
python
import torch
X_pt = torch.tensor([[4, 2], [-5, -3.]], dtype=torch.float32)
Xinv_pt = torch.inverse(X_pt)
print(Xinv_pt)Output:
tensor([[ 1.5000, 1.0000],
[-2.5000, -2.0000]])Contoh di TensorFlow:
python
import tensorflow as tf
X_tf = tf.Variable([[4, 2], [-5, -3.]], dtype=tf.float32)
Xinv_tf = tf.linalg.inv(X_tf)
print(Xinv_tf)Output:
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[ 1.4999999 , 0.99999994],
[-2.4999998 , -1.9999999 ]], dtype=float32)>Catatan
- Matriks invers
adalah matriks yang jika dikalikan dengan matriks , menghasilkan matriks identitas . - Invers matriks digunakan dalam penyelesaian sistem persamaan linear, di mana kita dapat menyelesaikan
dengan menggunakan . - Invers matriks dapat dihitung menggunakan berbagai pustaka seperti NumPy, PyTorch, dan TensorFlow, yang memiliki fungsi built-in untuk melakukan operasi ini.
- Invers matriks sangat berguna dalam berbagai aplikasi matematis dan komputasi ilmiah.
Invers Matriks Tanpa Penyelesaian
Pada bagian ini, kita akan membahas mengenai kasus di mana matriks yang diberikan tidak dapat diinversi (disebut singular matrix). Sebuah matriks dikatakan singular jika tidak memiliki invers. Ini terjadi ketika matriks tersebut tidak memiliki determinan yang tidak nol.
Contoh Matriks Singular
Misalkan kita memiliki matriks
python
X = np.array([[-4, 1], [-8, 2]])Matriks
Untuk menghitung invers matriks, kita bisa menggunakan fungsi np.linalg.inv(X). Namun, matriks ini adalah singular karena determinannya adalah nol. Matriks yang singular tidak memiliki invers.
Menghitung Determinan Matriks
Untuk memastikan apakah matriks ini singular atau tidak, kita bisa menghitung determinannya menggunakan np.linalg.det():
python
det_X = np.linalg.det(X)
print(det_X)Outputnya akan menunjukkan nilai determinan:
0.0Karena determinannya adalah 0, matriks ini adalah singular dan tidak dapat diinversi. Jika kita mencoba untuk menghitung invers dari matriks ini dengan menggunakan np.linalg.inv(X), kita akan mendapatkan kesalahan seperti ini:
python
Xinv = np.linalg.inv(X)Ini akan menghasilkan error:
LinAlgError: Singular matrixPenjelasan Mengapa Matriks Singular Tidak Bisa Dihitung Inversnya
Sebuah matriks tidak bisa diinversi (singular) jika baris atau kolom-kolomnya saling bergantung secara linier. Dalam hal ini, baris kedua
Matriks Non-Square
Selain itu, penting juga untuk diingat bahwa hanya matriks persegi (matriks dengan jumlah baris dan kolom yang sama) yang memiliki kemungkinan untuk memiliki invers. Jika kita mencoba untuk menghitung invers matriks non-persegi (misalnya matriks 2x3), kita akan mendapatkan error juga:
python
X_non_square = np.array([[1, 2, 3], [4, 5, 6]])
Xinv_non_square = np.linalg.inv(X_non_square) # This will throw an errorOutputnya akan seperti ini:
LinAlgError: Last 2 dimensions of the array must be squareIni menunjukkan bahwa invers hanya dapat dihitung pada matriks persegi.
Catatan
- Matriks singular (determinannya 0) tidak memiliki invers.
- Jika kita mencoba menghitung invers dari matriks singular, kita akan mendapatkan error
LinAlgError: Singular matrix. - Matriks non-persegi (jumlah baris dan kolom tidak sama) juga tidak dapat dihitung inversnya.
Penting untuk selalu memeriksa determinan matriks sebelum mencoba menghitung inversnya.
Matriks Ortogonal
Matriks ortogonal adalah matriks yang memiliki properti di mana kolom-kolom (atau baris-baris) matriks tersebut saling tegak lurus (orthogonal) dan memiliki panjang satu (norma unit). Dalam hal ini, kita akan membahas dua matriks ortogonal: matriks identitas
Matriks Identitas
Matriks identitas
Kolom pertama:
Kolom kedua:
Kolom ketiga:
Memeriksa Orthogonalitas Kolom
Untuk memastikan kolom-kolomnya saling ortogonal, kita dapat menghitung produk titik antara pasangan kolom:
Produk titik kolom 1 dan kolom 2:
pythonnp.dot(column_1, column_2) # Output: 0Produk titik kolom 1 dan kolom 3:
pythonnp.dot(column_1, column_3) # Output: 0Produk titik kolom 2 dan kolom 3:
pythonnp.dot(column_2, column_3) # Output: 0
Karena semua produk titiknya adalah nol, kolom-kolom dari matriks
Memeriksa Norma Kolom
Selanjutnya, kita memeriksa apakah norma setiap kolom adalah 1 (norma unit). Norma kolom dihitung dengan fungsi np.linalg.norm():
Norma kolom 1:
pythonnp.linalg.norm(column_1) # Output: 1.0Norma kolom 2:
pythonnp.linalg.norm(column_2) # Output: 1.0Norma kolom 3:
pythonnp.linalg.norm(column_3) # Output: 1.0
Karena norma setiap kolom adalah 1, kolom-kolom dari
Matriks Ortogonal
Matriks
Kita akan mengikuti langkah-langkah yang sama untuk matriks
Memeriksa Orthogonalitas Kolom
Menghitung produk titik antar kolom-kolom dari
Produk titik kolom 1 dan kolom 2:
pythontorch.dot(Kcol_1, Kcol_2) # Output: 0Produk titik kolom 1 dan kolom 3:
pythontorch.dot(Kcol_1, Kcol_3) # Output: 0Produk titik kolom 2 dan kolom 3:
pythontorch.dot(Kcol_2, Kcol_3) # Output: 0
Karena semua produk titiknya adalah nol, kolom-kolom dari
Memeriksa Norma Kolom
Kemudian kita memeriksa norma kolom-kolom
Norma kolom 1:
pythontorch.norm(Kcol_1) # Output: 1Norma kolom 2:
pythontorch.norm(Kcol_2) # Output: 1Norma kolom 3:
pythontorch.norm(Kcol_3) # Output: 1
Karena norma setiap kolom adalah 1, kolom-kolom dari
Memeriksa Matriks Ortogonal
Untuk memastikan bahwa
python
torch.matmul(K.T, K) # Hasilnya mendekati matriks identitasOutput yang diperoleh adalah matriks yang hampir sama dengan matriks identitas, dengan sedikit kesalahan numerik karena representasi floating-point:
Karena hasilnya sangat dekat dengan matriks identitas, kita dapat menyimpulkan bahwa
- Matriks
adalah matriks ortogonal karena kolom dan barisnya ortonormal (salin ortogonal dan norma unit). - Matriks
juga ortogonal karena kolom-kolomnya ortonormal, dan hasil perkalian mendekati matriks identitas.
Matriks ortogonal adalah matriks yang memiliki kolom dan baris ortonormal, dan mereka sangat berguna dalam berbagai aplikasi, seperti rotasi dan transformasi dalam geometri dan aljabar linier.